Increasing successful detections using data resampling
Fraud Detection in Python

Charlotte Werger
Data Scientist
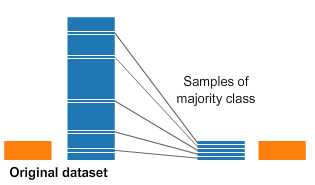
Undersampling
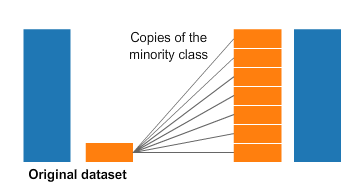
Oversampling
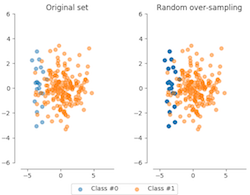
Oversampling in Python
from imblearn.over_sampling import RandomOverSamplermethod = RandomOverSampler() X_resampled, y_resampled = method.fit_resample(X, y)compare_plots(X_resampled, y_resampled, X, y)
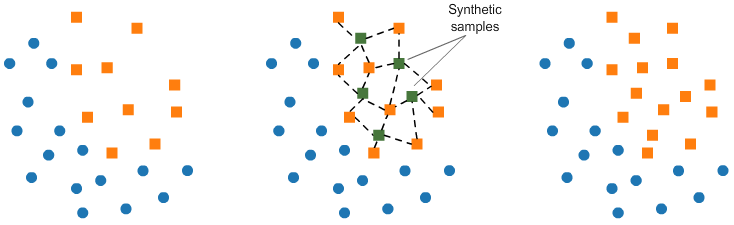
Synthetic Minority Oversampling Technique (SMOTE)
1 https://www.kaggle.com/rafjaa/resampling-strategies-for-imbalanced-datasets

