Other clustering fraud detection methods
Fraud Detection in Python

Charlotte Werger
Data Scientist
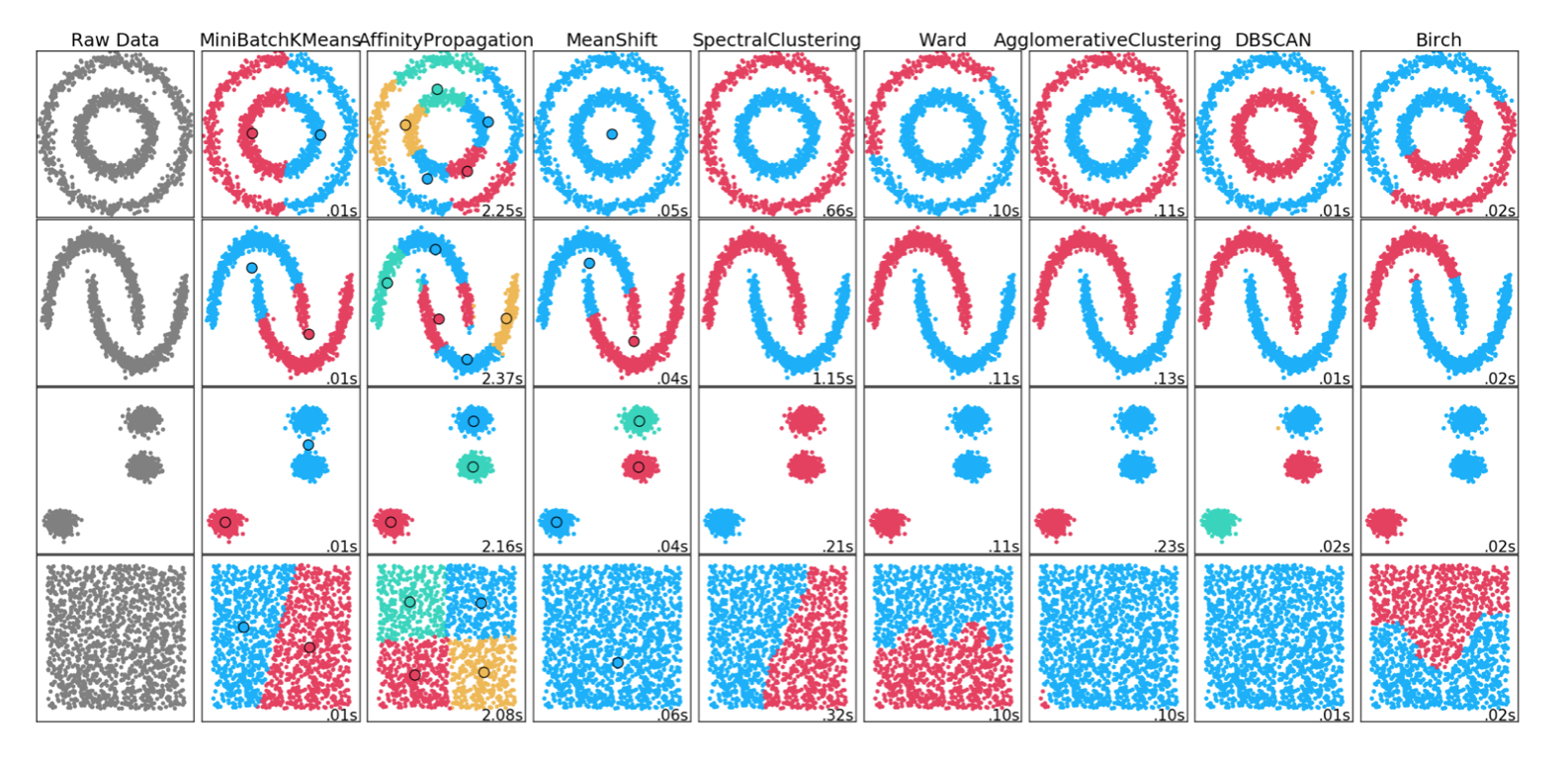
There are many different clustering methods
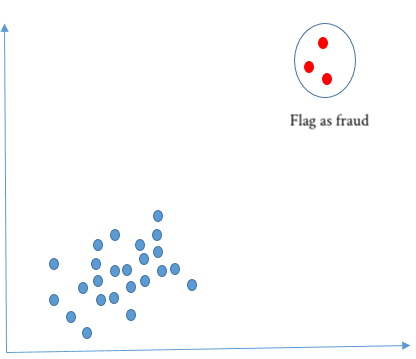
And different ways of flagging fraud: using smallest clusters
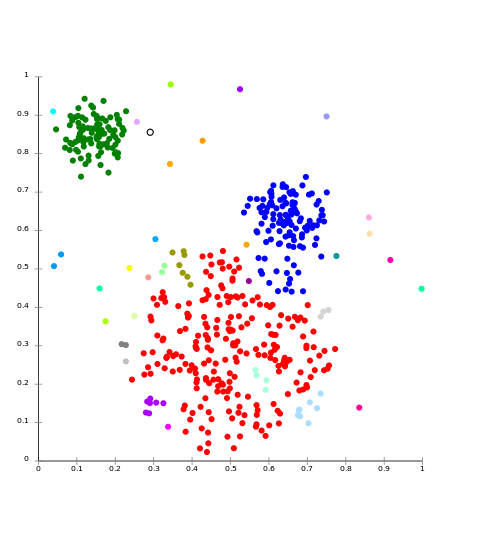
In reality it looks more like this
Fraud Detection in Python
Charlotte Werger
Data Scientist

