Clustering methods to detect fraud
Fraud Detection in Python

Charlotte Werger
Data Scientist
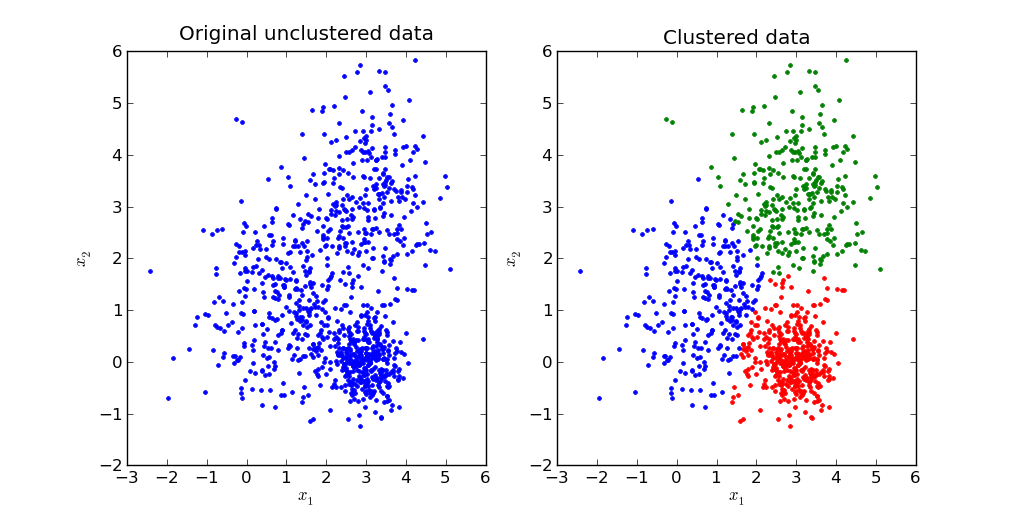
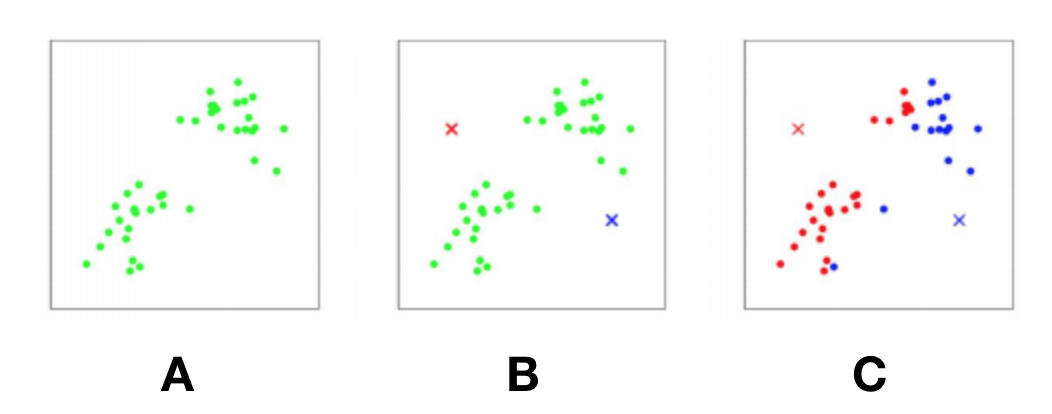
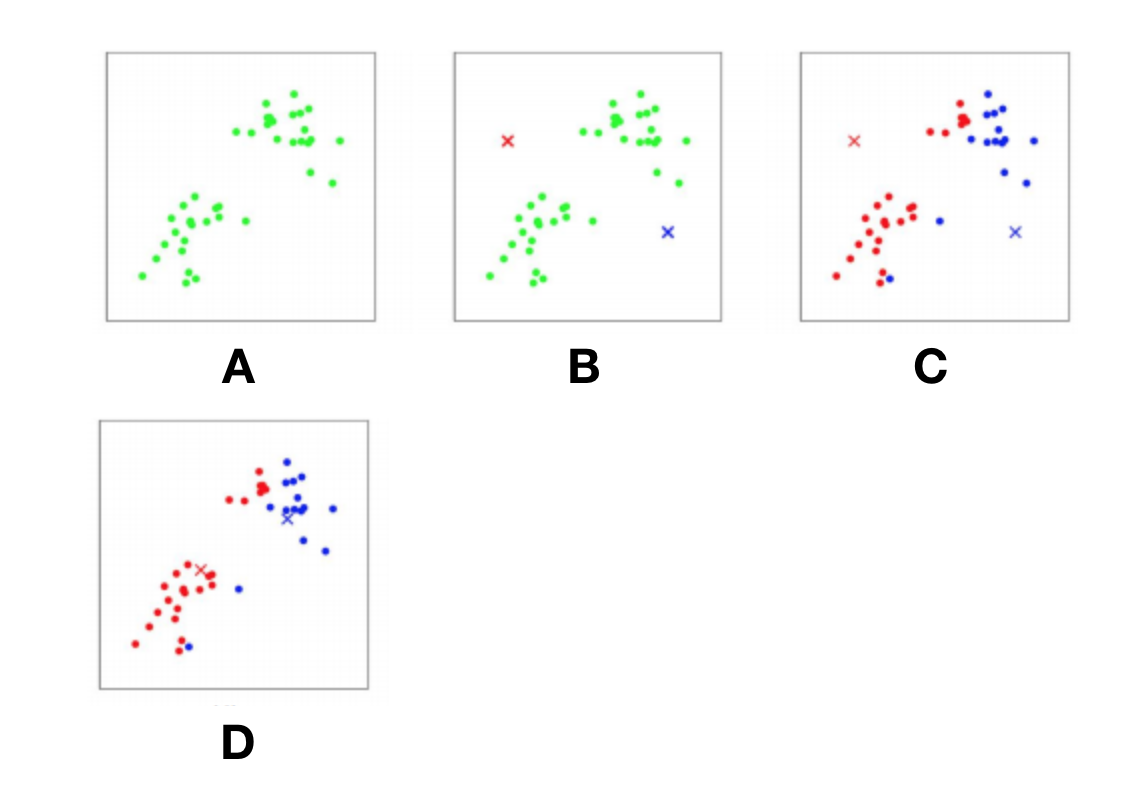
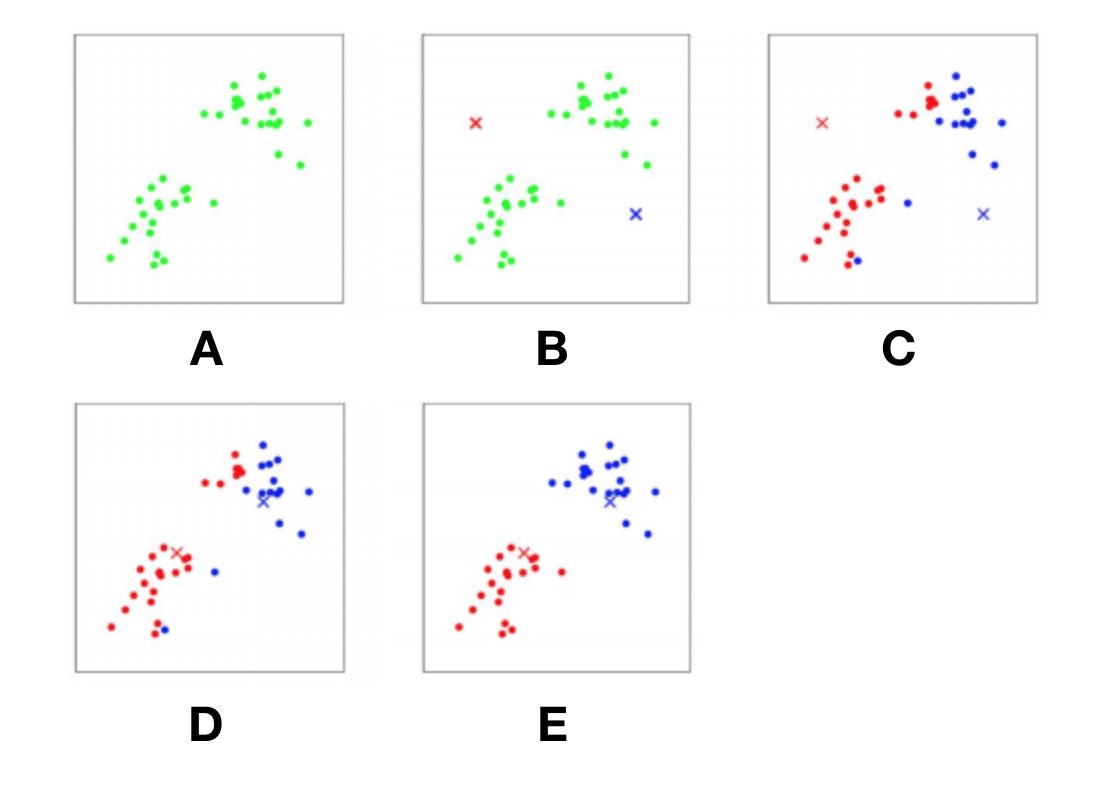
Clustering: trying to detect patterns in data
K-means clustering: using the distance to cluster centroids
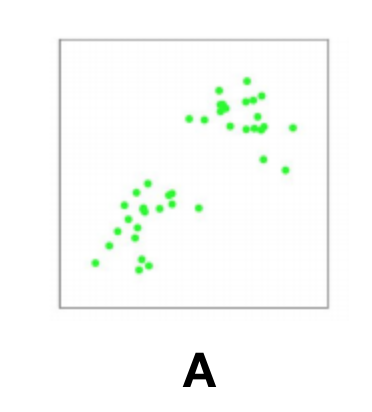
K-means clustering: using the distance to cluster centroids
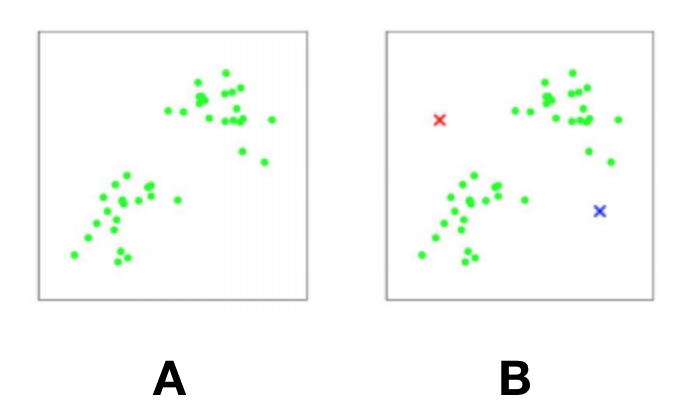
K-means clustering: using the distance to cluster centroids
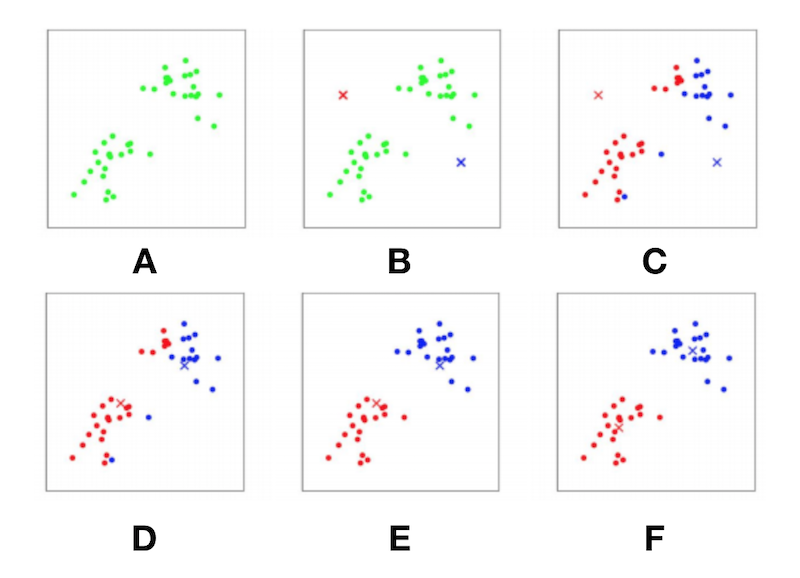
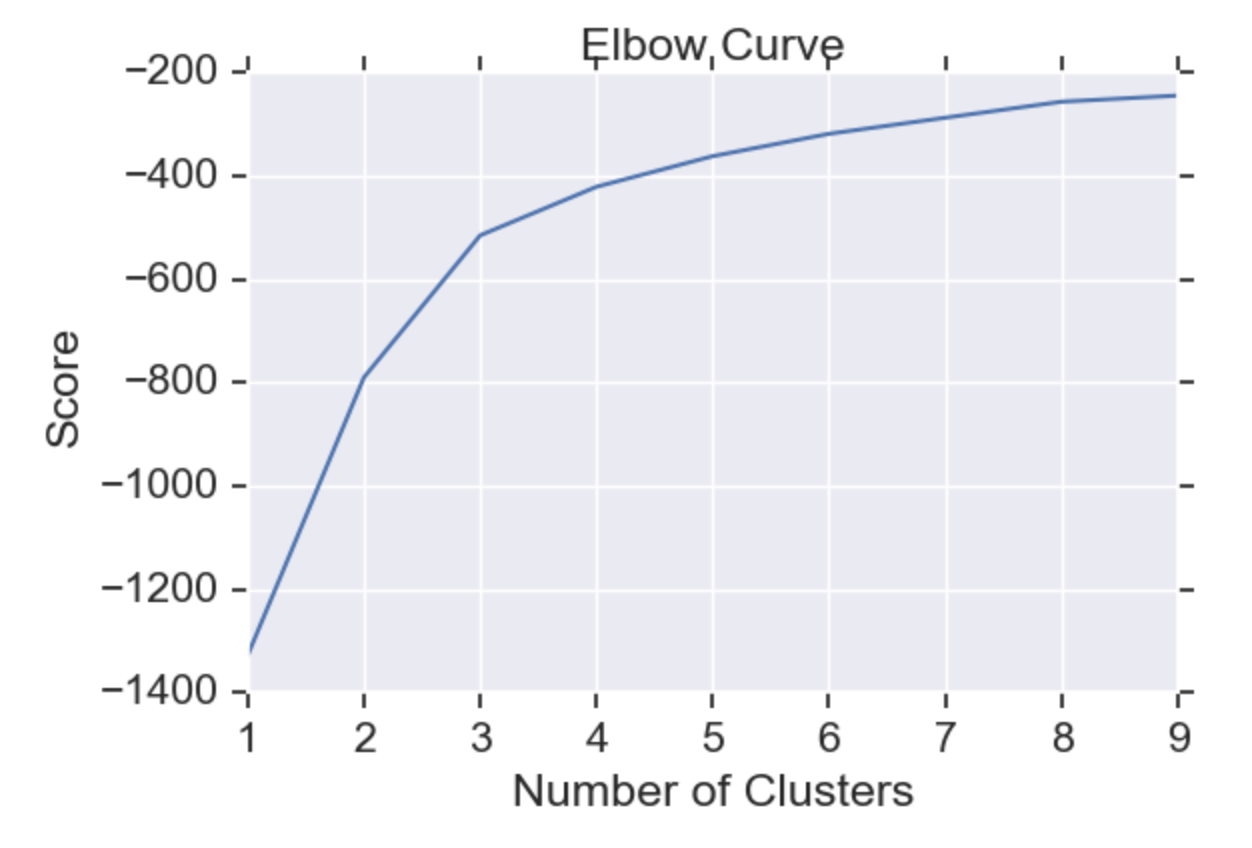
The elbow curve