Fraud Detection in Python
Charlotte Werger
Data Scientist
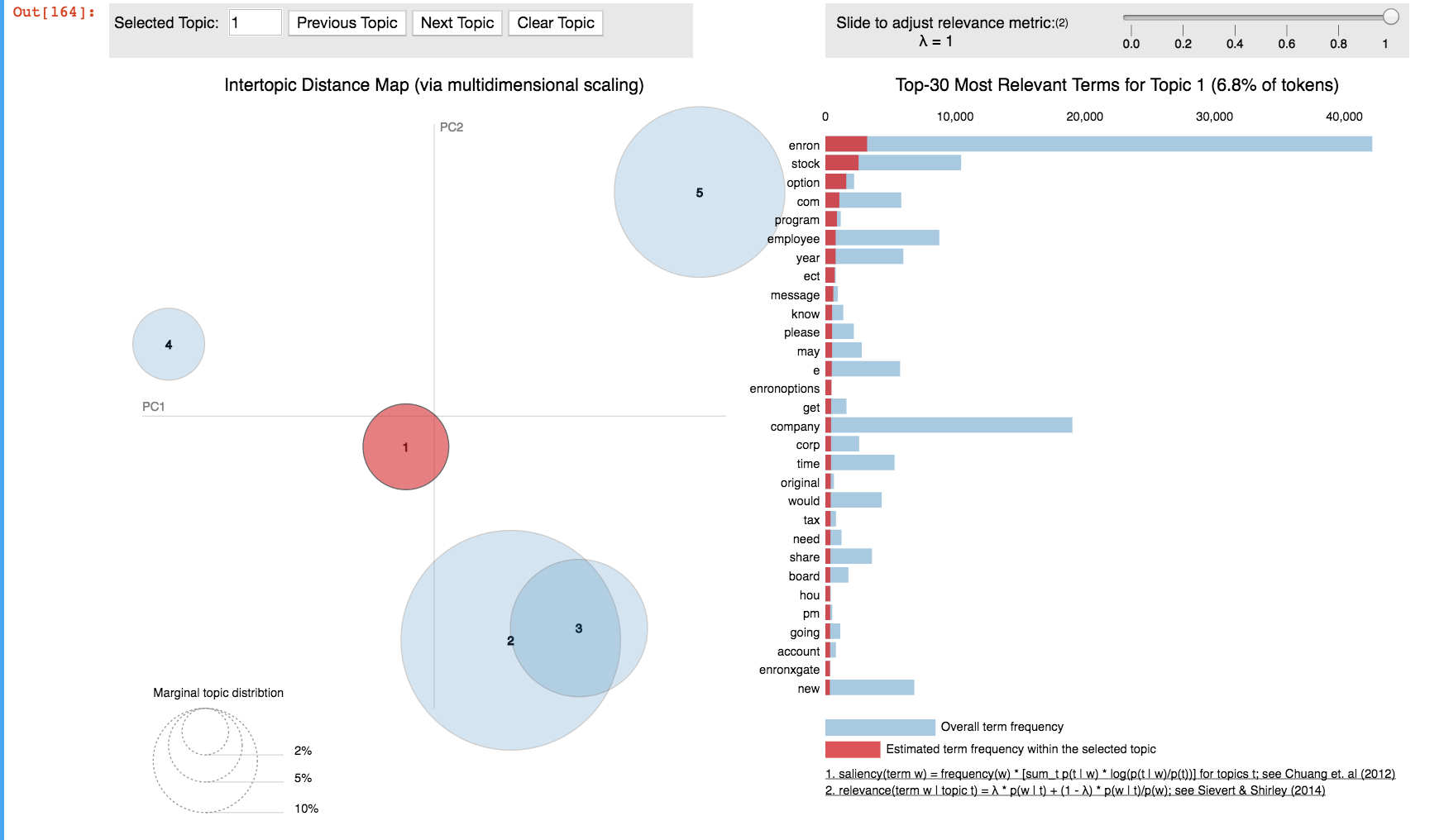
import pyLDAvis.gensim
lda_display = pyLDAvis.gensim.prepare(ldamodel, corpus, dictionary, sort_topics=False)
pyLDAvis.display(lda_display)
def get_topic_details(ldamodel, corpus): topic_details_df = pd.DataFrame() for i, row in enumerate(ldamodel[corpus]): row = sorted(row, key=lambda x: (x[1]), reverse=True) for j, (topic_num, prop_topic) in enumerate(row): if j == 0: # => dominant topic wp = ldamodel.show_topic(topic_num) topic_details_df = topic_details_df.append(pd.Series([topic_num, prop_topic]), ignore_index=True) topic_details_df.columns = ['Dominant_Topic', '% Score'] return topic_details_df
contents = pd.DataFrame({'Original text':text_clean}) topic_details = pd.concat([get_topic_details(ldamodel, corpus), contents], axis=1) topic_details.head()
Dominant_Topic % Score Original text 0 0.0 0.989108 [investools, advisory, free, ... 1 0.0 0.993513 [forwarded, richard, b, ... 2 1.0 0.964858 [hey, wearing, target, purple, ... 3 0.0 0.989241 [leslie, milosevich, santa, clara, ...