Measuring Segregation: The Index of Dissimilarity
Analyzing US Census Data in Python

Lee Hachadoorian
Asst. Professor of Instruction, Temple University
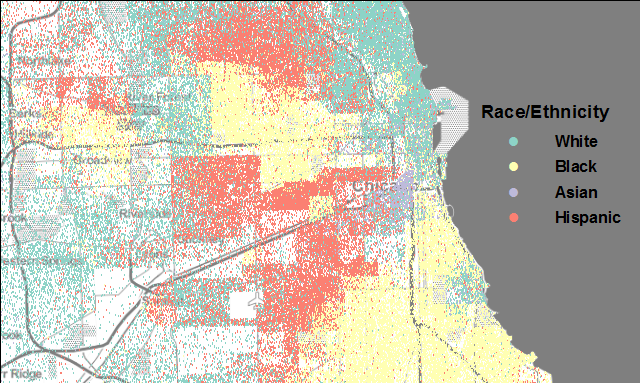
What is Segregation?
Index of Dissimilarity Formula
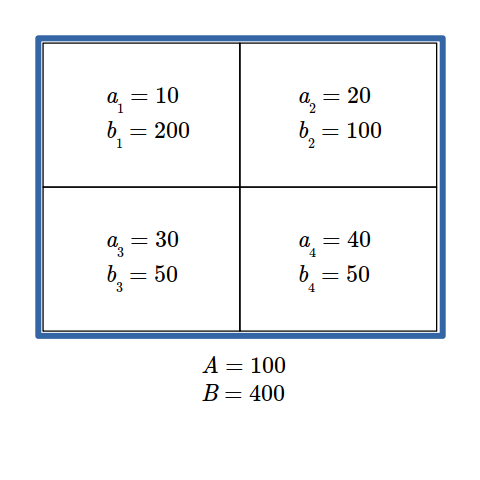
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula
Index of Dissimilarity Formula

