Big Data Fundamentals with PySpark
Upendra Devisetty
Science Analyst, CyVerse
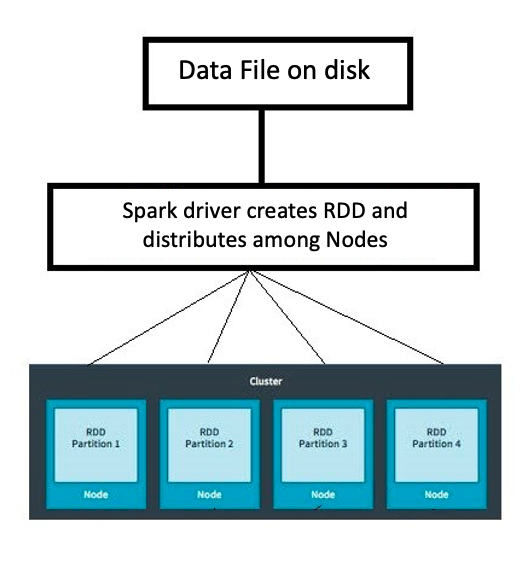
Resilient Distributed Datasets
Resilient: Ability to withstand failures
Distributed: Spanning across multiple machines
Datasets: Collection of partitioned data e.g, Arrays, Tables, Tuples etc.,
Parallelizing an existing collection of objects
External datasets:
Files in HDFS
Objects in Amazon S3 bucket
lines in a text file
From existing RDDs
parallelize()
numRDD = sc.parallelize([1,2,3,4])
helloRDD = sc.parallelize("Hello world")
type(helloRDD)
<class 'pyspark.rdd.PipelinedRDD'>
textFile()
fileRDD = sc.textFile("README.md")
type(fileRDD)
A partition is a logical division of a large distributed data set
parallelize() method
numRDD = sc.parallelize(range(10), minPartitions = 6)
fileRDD = sc.textFile("README.md", minPartitions = 6)
getNumPartitions()