RDD operations in PySpark
Big Data Fundamentals with PySpark

Upendra Devisetty
Science Analyst, CyVerse
Overview of PySpark operations

- Transformations create new RDDs
- Actions perform computation on the RDDs
RDD Transformations
- Transformations follow Lazy evaluation

Basic RDD Transformations
map(),filter(),flatMap(), andunion()
map() Transformation
- map() transformation applies a function to all elements in the RDD
![]()
RDD = sc.parallelize([1,2,3,4])
RDD_map = RDD.map(lambda x: x * x)
filter() Transformation
- Filter transformation returns a new RDD with only the elements that pass the condition

RDD = sc.parallelize([1,2,3,4])
RDD_filter = RDD.filter(lambda x: x > 2)
flatMap() Transformation
- flatMap() transformation returns multiple values for each element in the original RDD
![]()
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))
union() Transformation
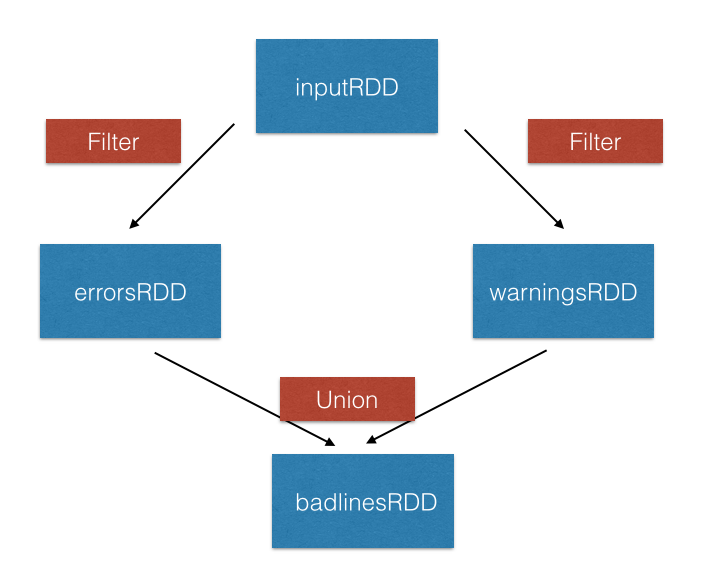
inputRDD = sc.textFile("logs.txt")
errorRDD = inputRDD.filter(lambda x: "error" in x.split())
warningsRDD = inputRDD.filter(lambda x: "warnings" in x.split())
combinedRDD = errorRDD.union(warningsRDD)

