Principal component analysis
Dimensionality Reduction in Python

Jeroen Boeye
Head of Machine Learning, Faktion
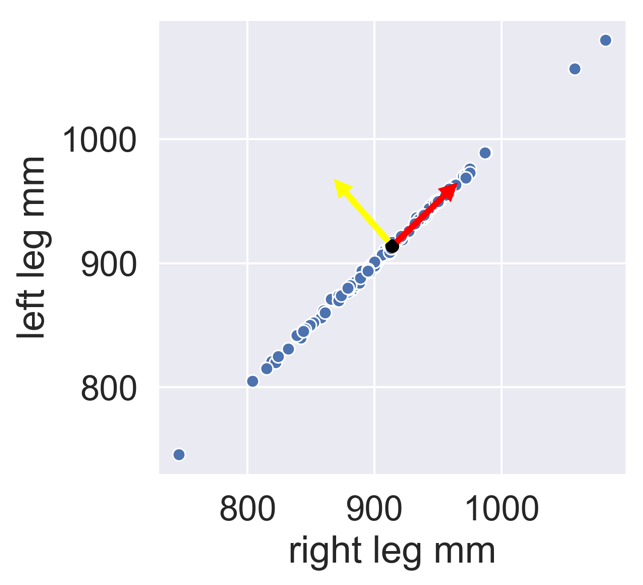
PCA concept
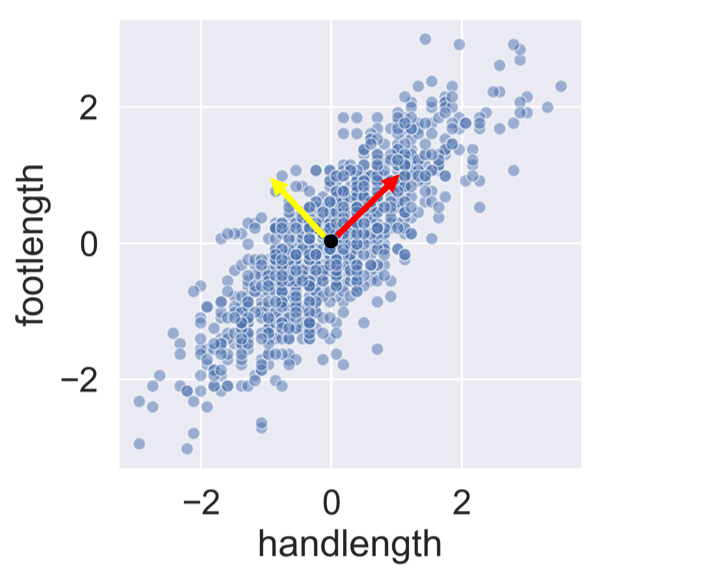
PCA concept
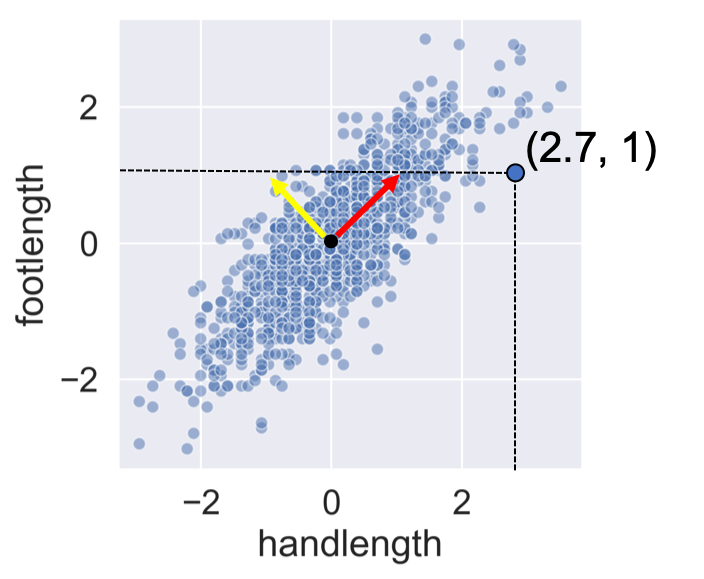
PCA concept
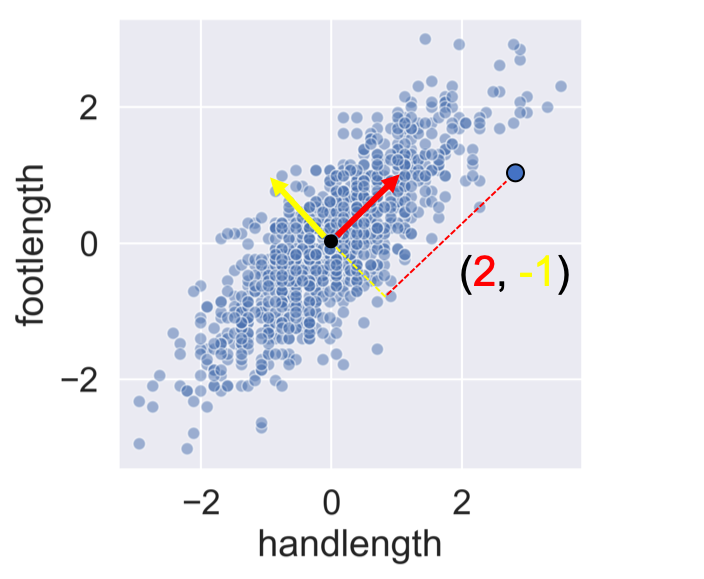
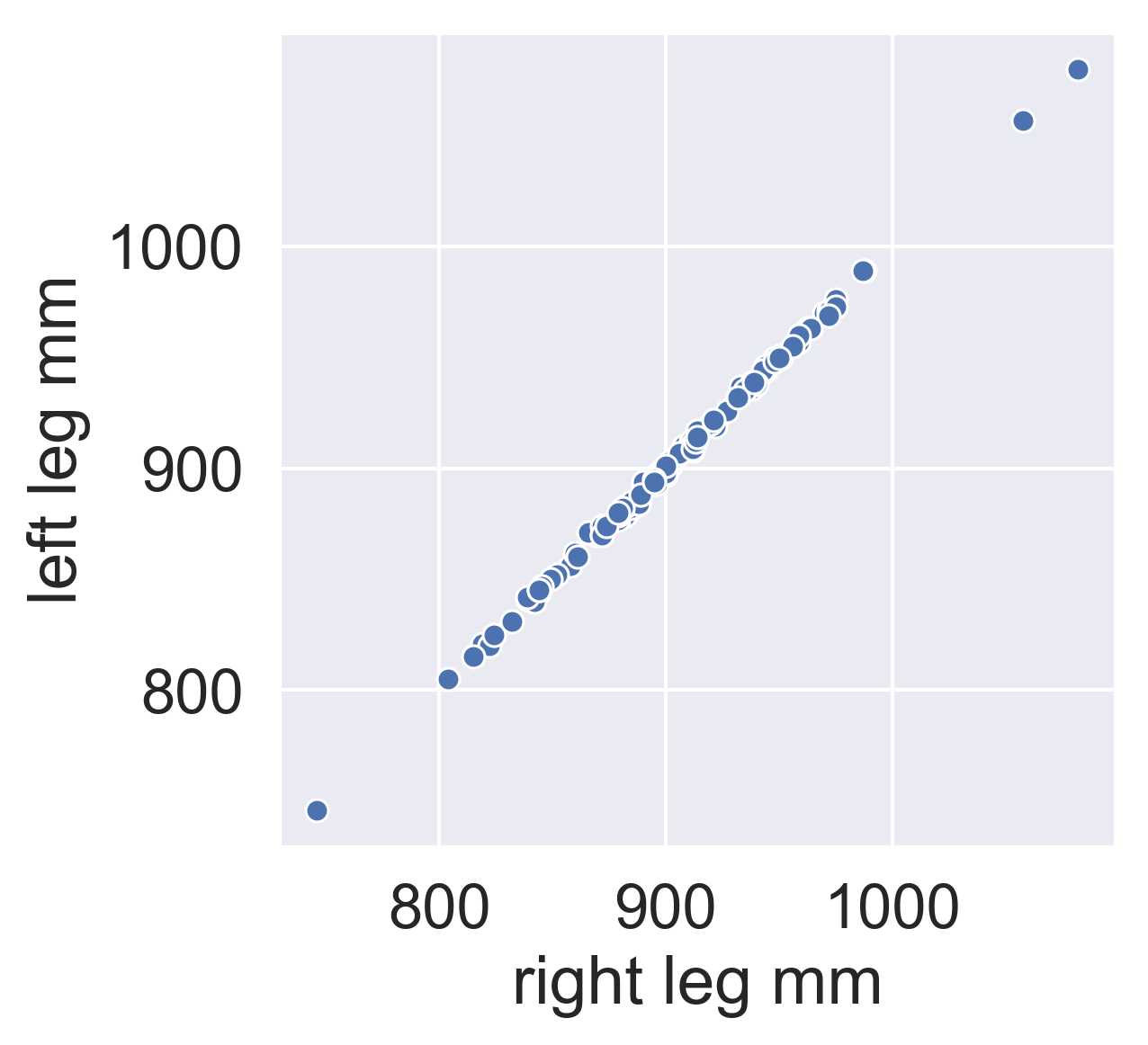
PCA removes correlation
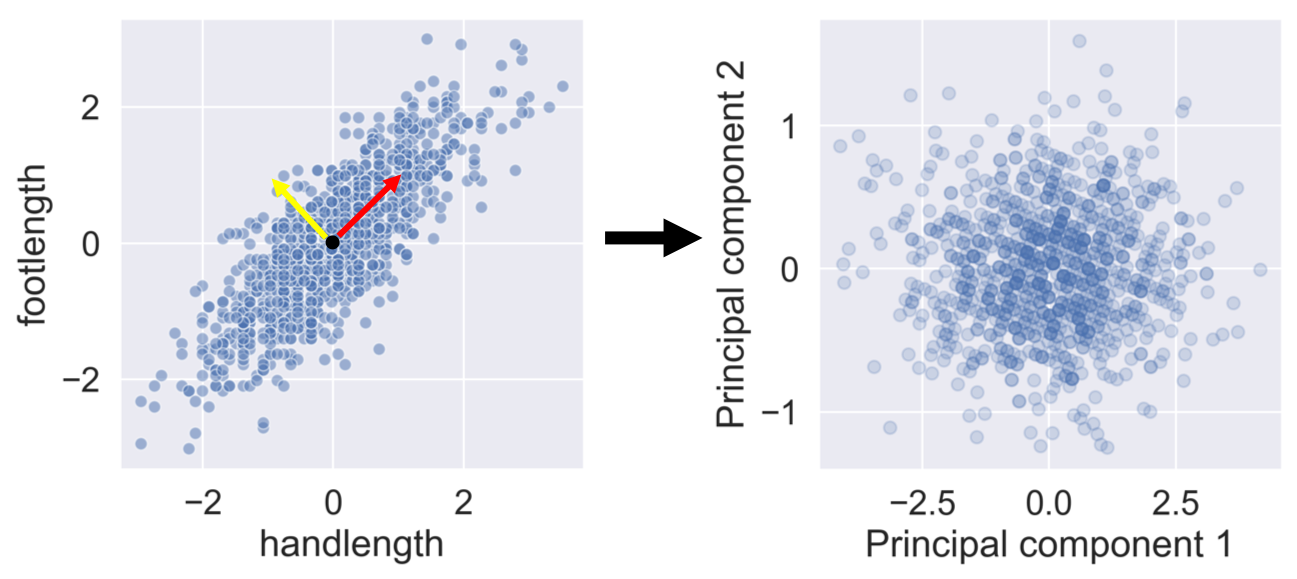
PCA for dimensionality reduction
PCA for dimensionality reduction
Dimensionality Reduction in Python
Jeroen Boeye
Head of Machine Learning, Faktion

