Tree-based feature selection
Dimensionality Reduction in Python

Jeroen Boeye
Head of Machine Learning, Faktion
Random forest classifier
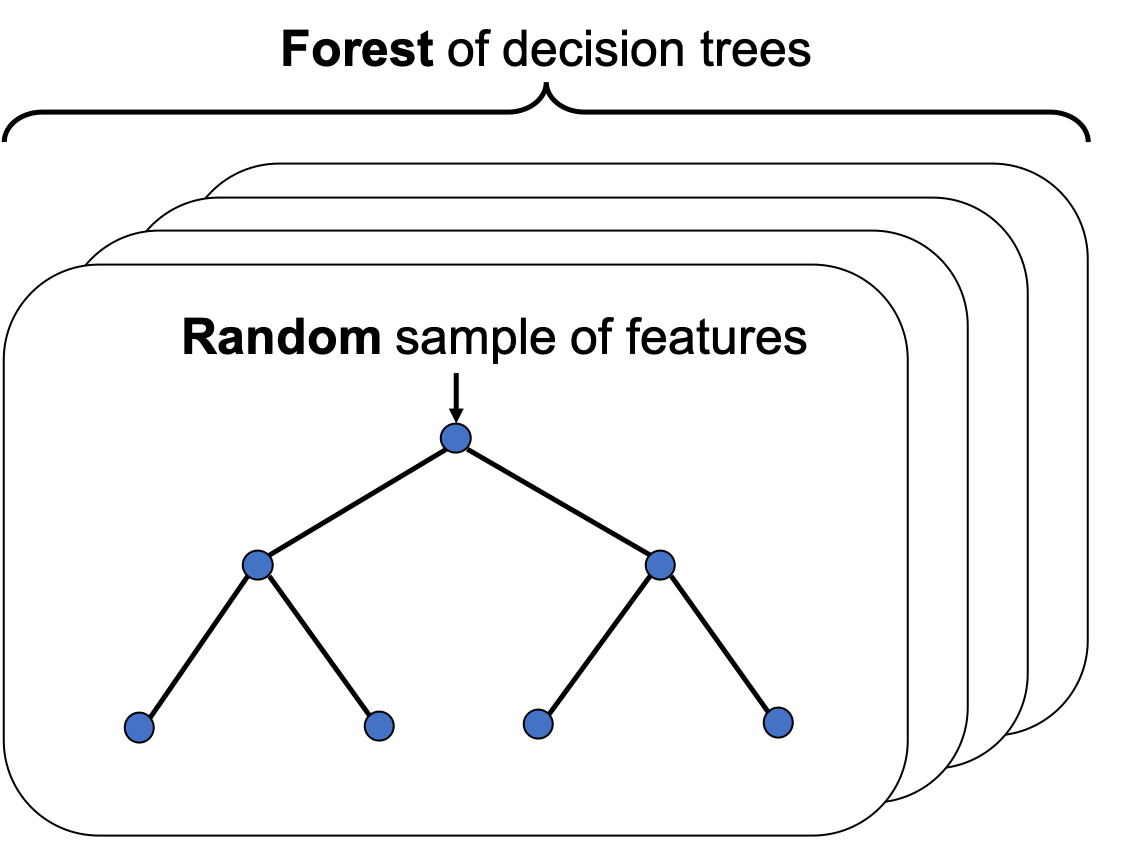
Random forest classifier

Dimensionality Reduction in Python
Jeroen Boeye
Head of Machine Learning, Faktion

