PCA applications
Dimensionality Reduction in Python

Jeroen Boeye
Head of Machine Learning, Faktion
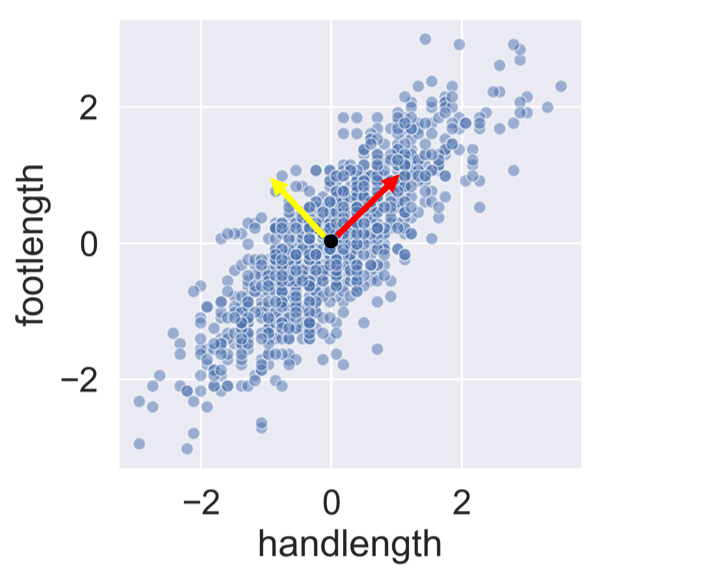
Understanding the components
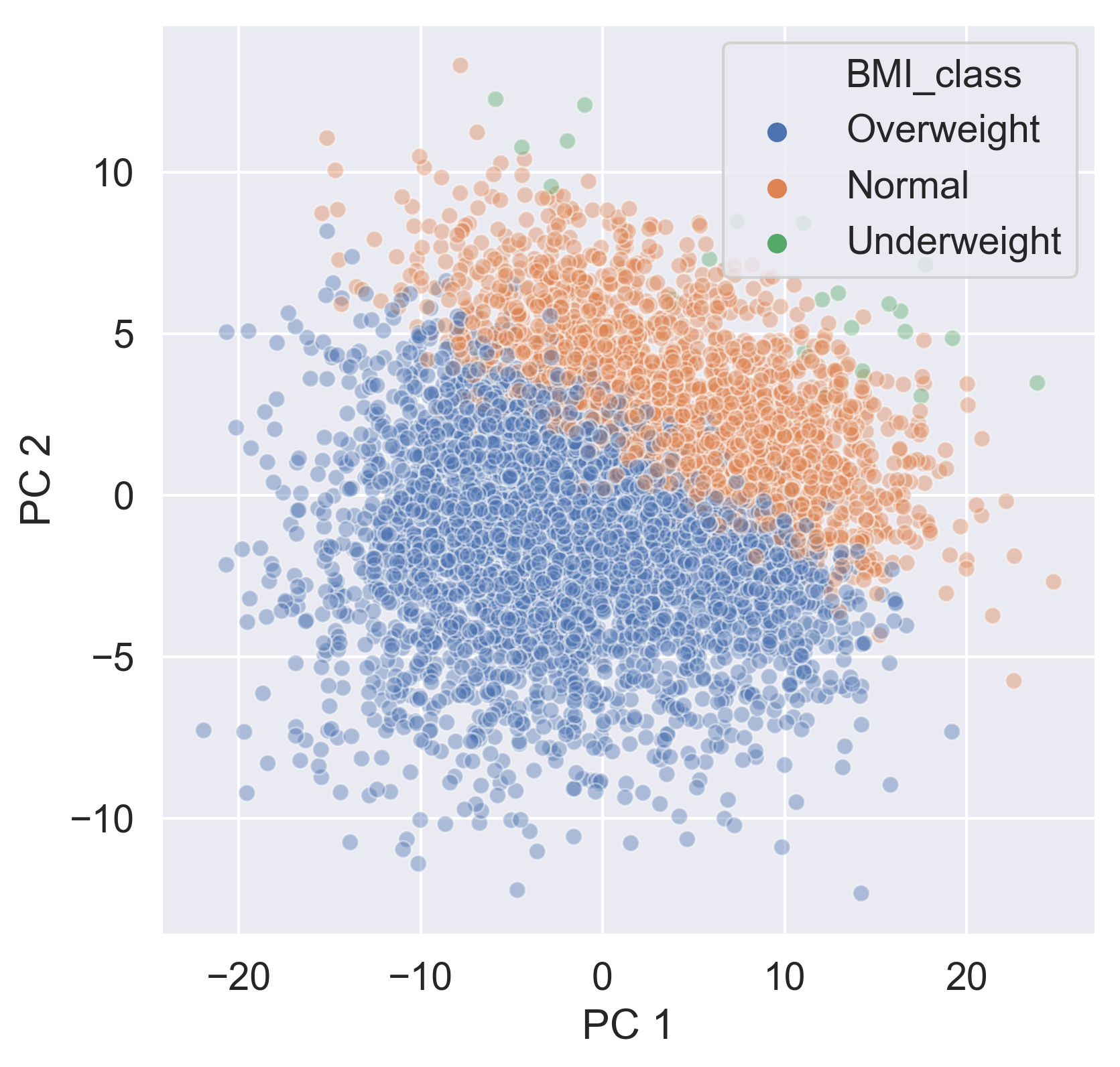
PCA for data exploration
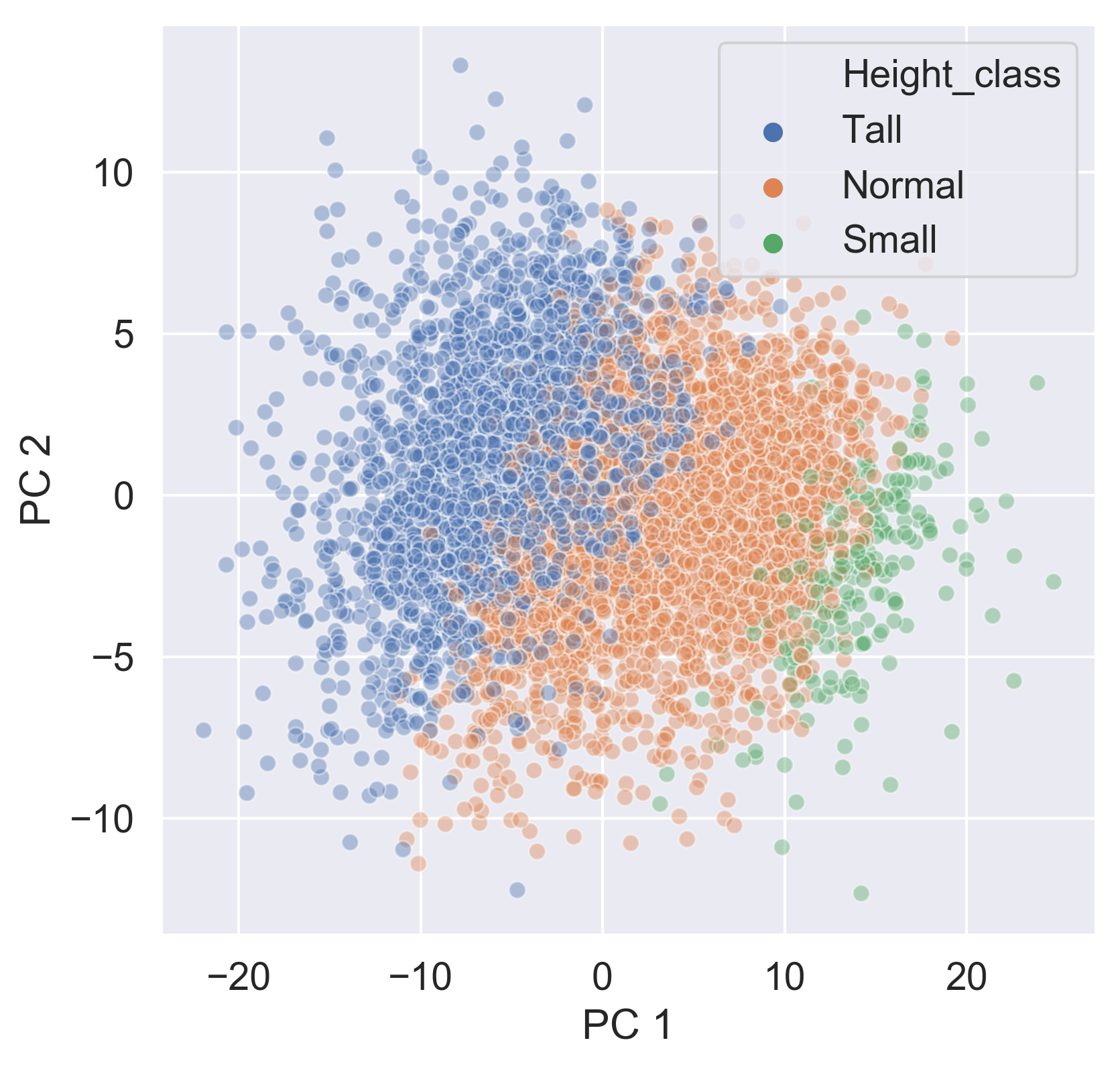
Checking the effect of categorical features
Checking the effect of categorical features
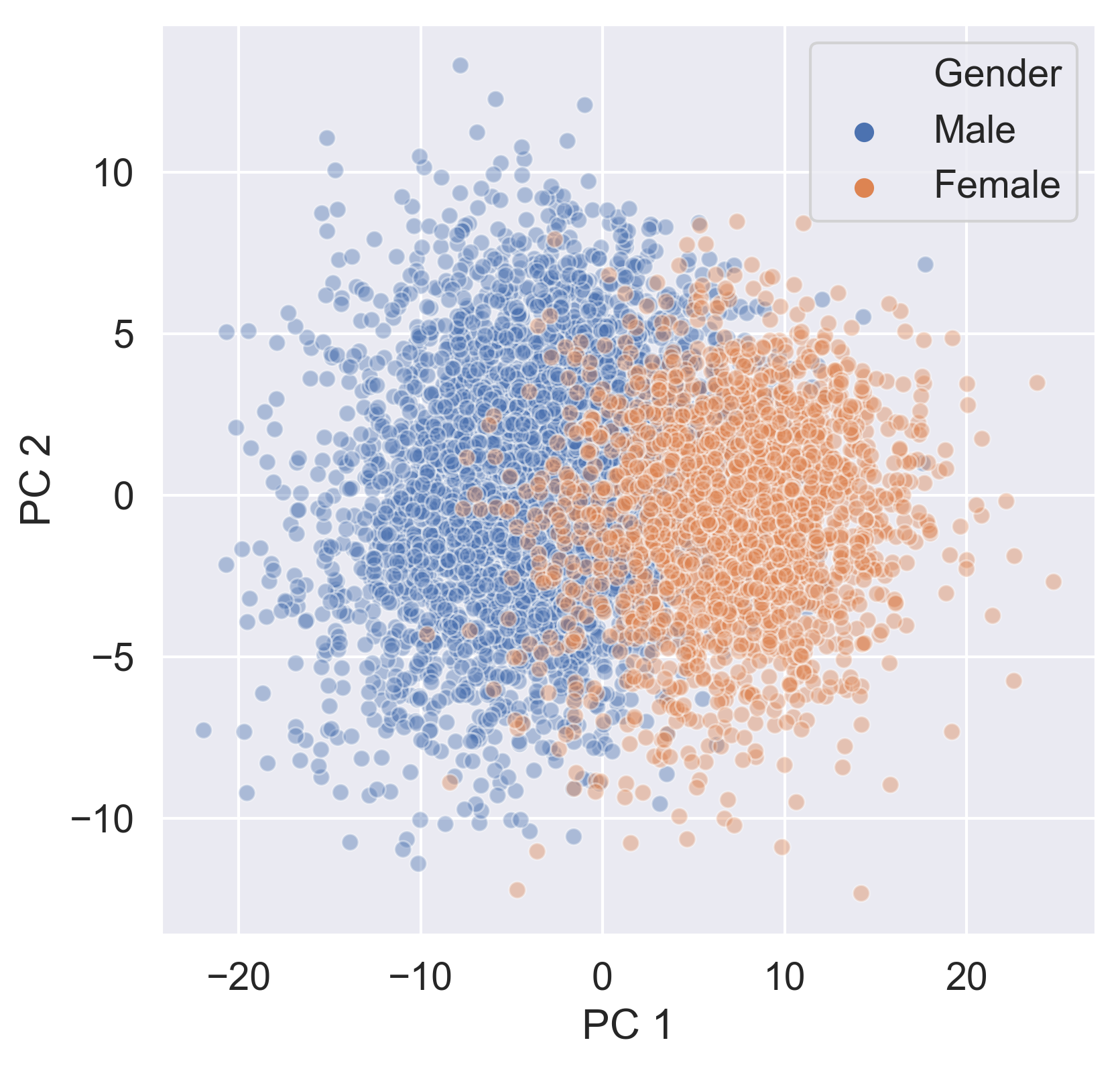
Checking the effect of categorical features