Supervised learning pipelines
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
Labeled data
- Feature variables (shorthand:
X) - Labels or class (shorthand:
y)
credit_scoring.head(4)
checking_status duration ... foreign_worker class
0 '<0' 6 ... yes good
1 '0<=X<200' 48 ... yes bad
2 'no checking' 12 ... yes good
3 '<0' 42 ... yes good
Feature engineering
- Most classifiers expect numeric features
- Need to convert string columns to numbers
Preprocess using LabelEncoder from sklearn.preprocessing:
le = LabelEncoder()
le.fit_transform(credit_scoring['checking_status'])[:4]
array([1, 0, 3, 1])
Model fitting
.fit(features, labels).predict(features)
features, labels = credit_scoring.drop('class', 1), credit_scoring['class']model_nb = GaussianNB() model_nb.fit(features, labels) model_nb.predict(features.head(5))
['good' 'bad' 'good' 'bad' 'good']
60% accuracy on first 5 examples.
Model selection
.fit()optimizes the parameters of the given model- What about other models?
AdaBoostClassifier outperforms GaussianNB on first five data points:
model_ab = AdaBoostClassifier()
model_ab.fit(features, labels)
model_ab.predict(features.head(5))
numpy.array(labels[0:5])
['good' 'bad' 'good' 'good' 'bad']
['good' 'bad' 'good' 'good' 'bad']
Performance assessment
Larger sample sizes $\Rightarrow$ better accuracy estimates:
from sklearn.metrics import accuracy_score
accuracy_score(labels, model_nb.predict(features)) # naive bayes
0.706
accuracy_score(labels, model_ab.predict(features)) # adaboost
0.802
What is wrong with this calculation?
Overfitting and data splitting
Overfitting: a model will always perform better on the data it was trained on than on unseen data.
Train on X_train, y_train, assess accuracy on X_test, y_test:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)GaussianNB().fit(X_train, y_train).predict(X_test)
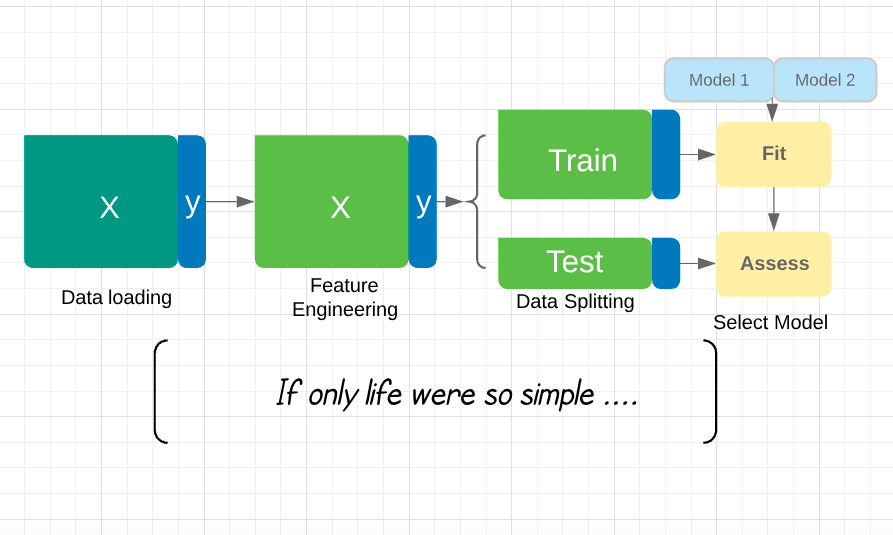
So, what is this course about?
- Scalable ways to tune your pipeline.
- Making sure your predictions are relevant by involving domain experts.
- Making sure your model continues to perform well over time.
- Fitting models when you don't have enough labels.
Could you have prevented the mortgage crisis?
Designing Machine Learning Workflows in Python

