Loss functions Part I
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
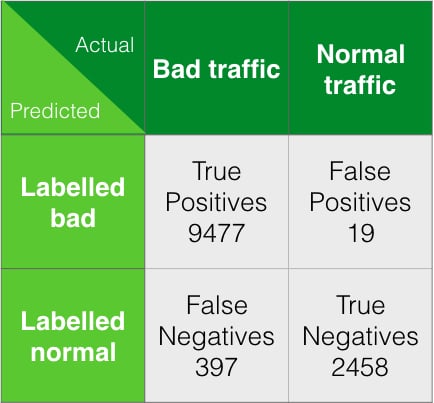
False positives vs false negatives

False positives vs false negatives

False positives vs false negatives

False positives vs false negatives

The confusion matrix