Model deployment
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
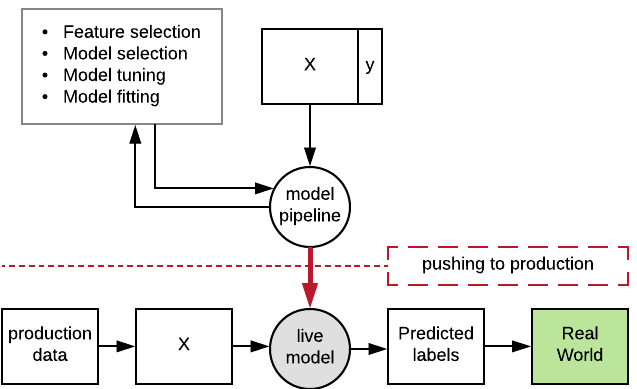
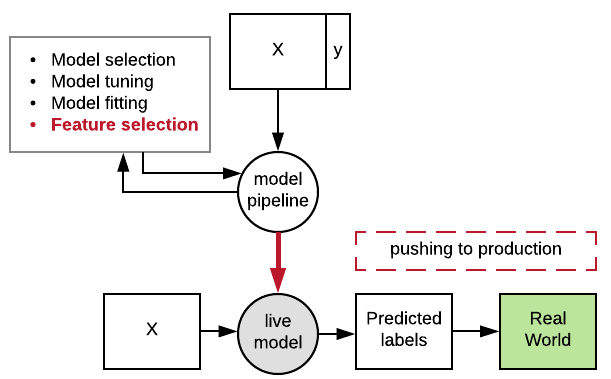
Serializing your pipeline
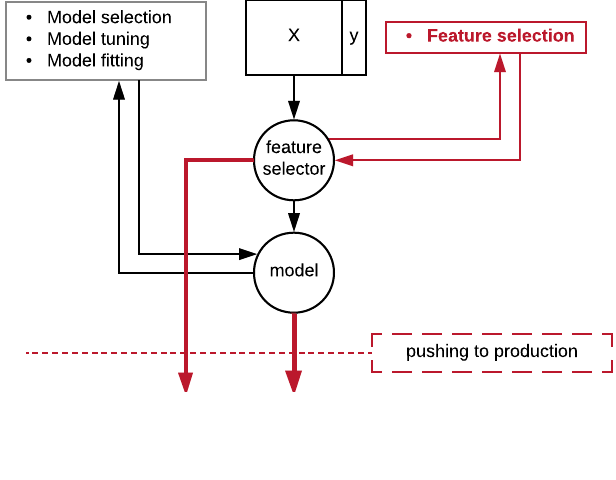
Serializing your pipeline
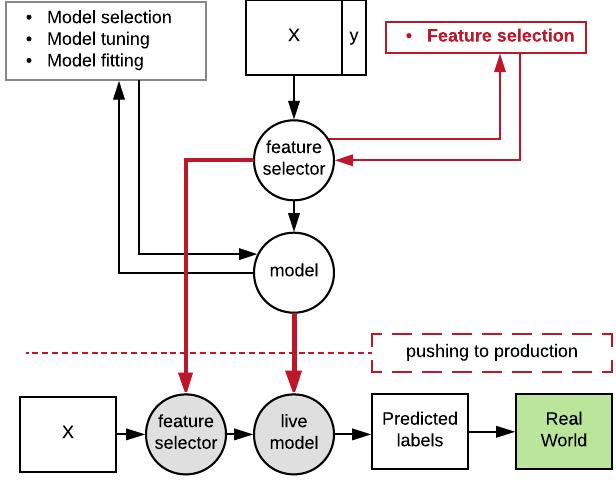
Serializing your pipeline
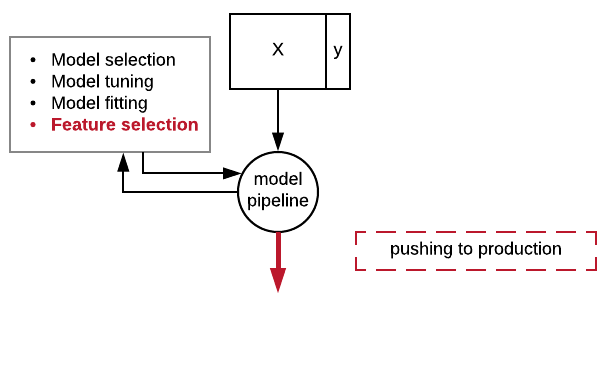
Serializing your pipeline
Designing Machine Learning Workflows in Python
Dr. Chris Anagnostopoulos
Honorary Associate Professor

