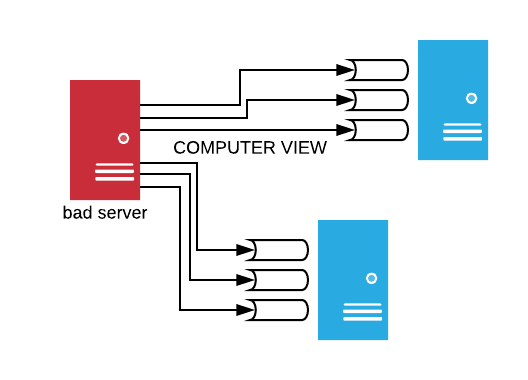
Data fusion
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
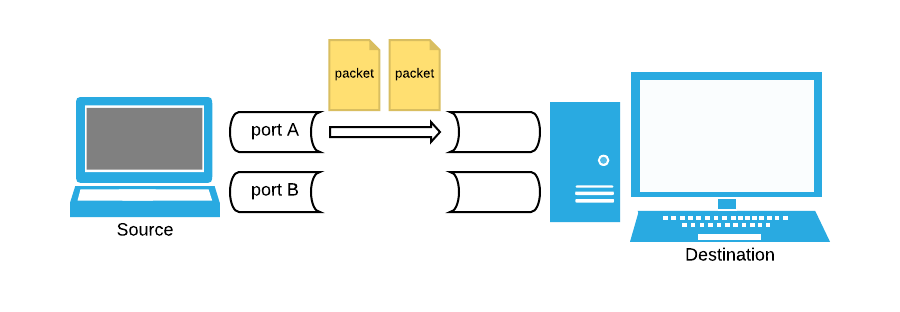
Computers, ports, and protocols
Labeling events versus labeling computers
A single event cannot be easily labeled.

But an entire computer is either infected or not.