Labels, weak labels and truth
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
From features to labels
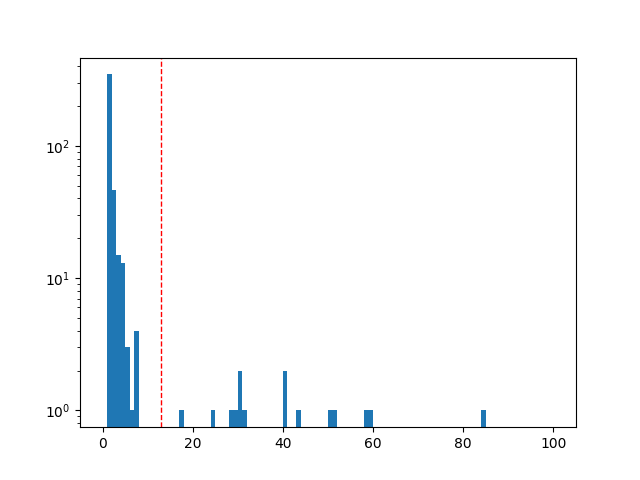
Convert a feature into a labeling heuristic:
X_train, X_test, y_train, y_test = train_test_split(X, y)
y_weak_train = X_train['unique_ports'] > 15
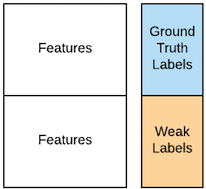
From features to labels
X_train_aug = pd.concat([X_train, X_train])
y_train_aug = pd.concat([pd.Series(y_train), pd.Series(y_weak_train)])
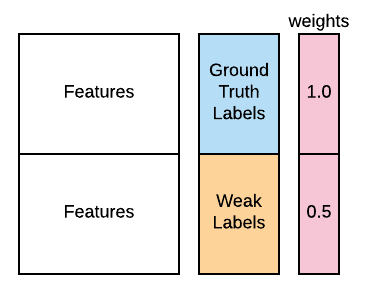
weights = [1.0]*len(y_train) + [0.1]*len(y_weak_train)

