From workflows to pipelines
Designing Machine Learning Workflows in Python

Dr. Chris Anagnostopoulos
Honorary Associate Professor
The power of grid search
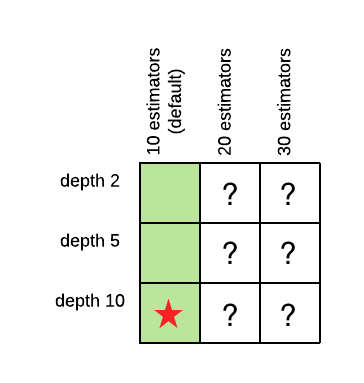
The power of grid search
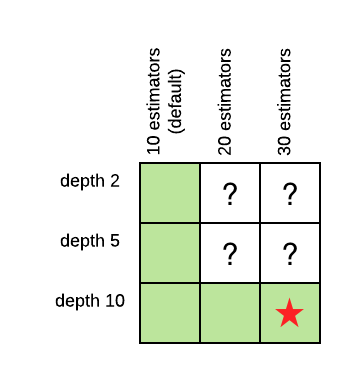
The power of grid search
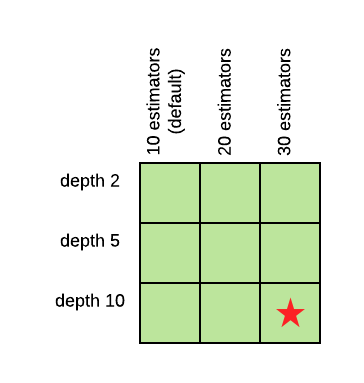
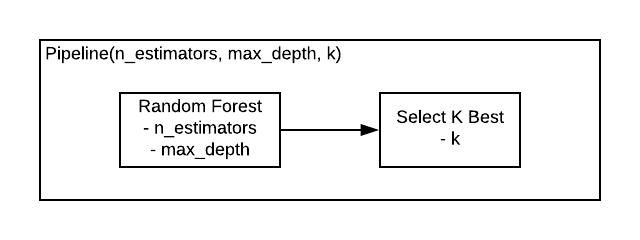
Pipelines
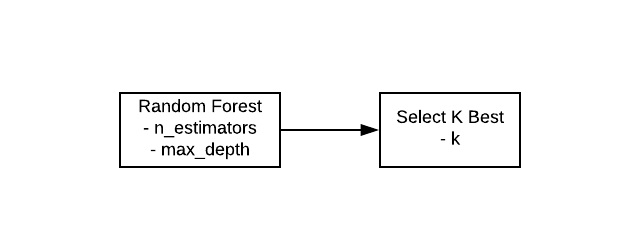
Pipelines
Designing Machine Learning Workflows in Python
Dr. Chris Anagnostopoulos
Honorary Associate Professor

