Grouping and summarizing
Case Study: Exploratory Data Analysis in R

Dave Robinson
Chief Data Scientist, DataCamp
Using “% of Yes votes” as a summary

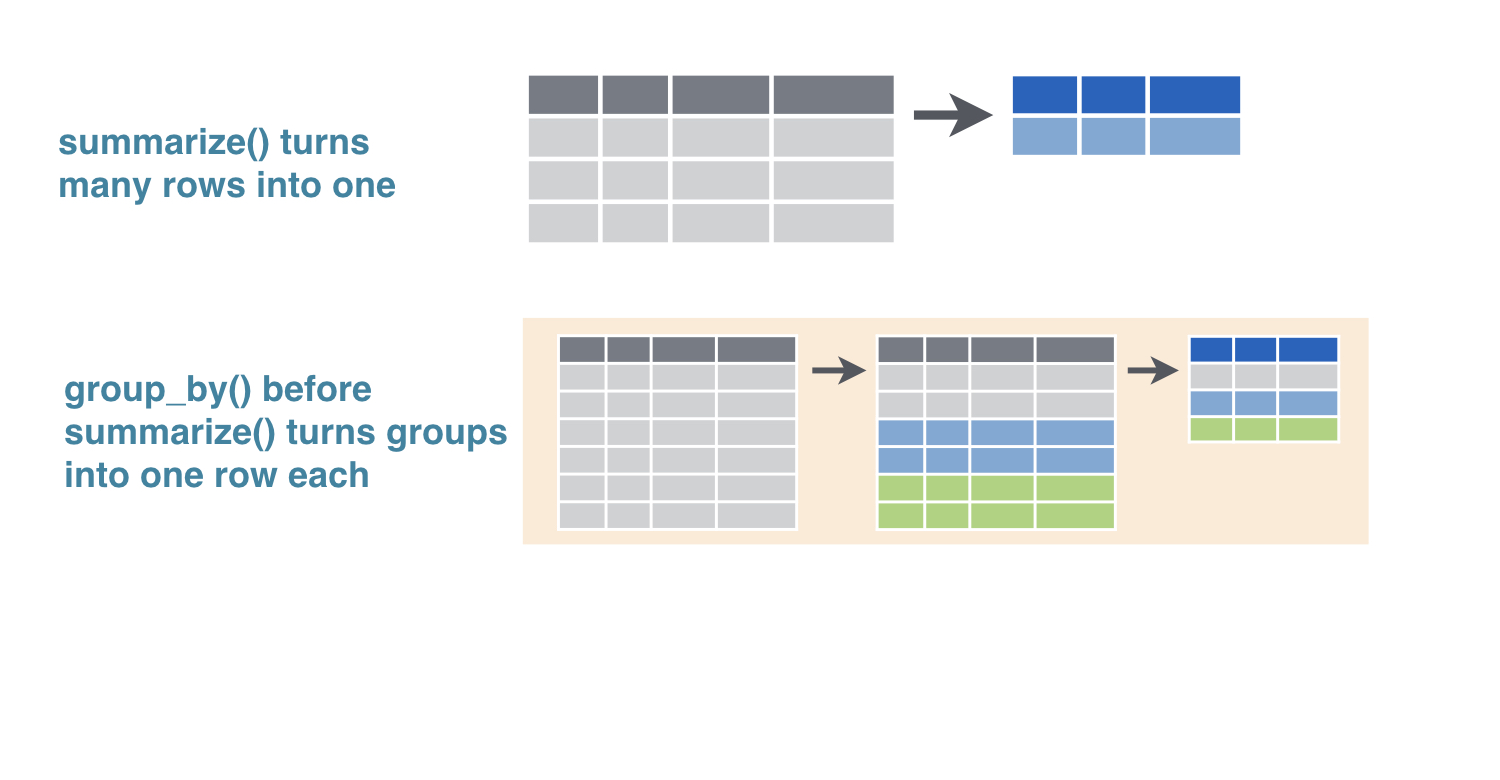
dplyr verb: summarize
summarize() turns many rows into one

dplyr verb: group_by
summarize()turns many rows into onegroup_by()beforesummarize()turns groups into one row each