Introduction to Text Analysis in R
Maham Faisal Khan
Senior Data Science Content Developer
stop_words
# A tibble: 1,149 x 2 word lexicon <chr> <chr> 1 a SMART 2 a's SMART 3 able SMART 4 about SMART 5 above SMART # … with 1,144 more rows
tribble( ~word, ~lexicon, "roomba", "CUSTOM", "2", "CUSTOM" )
# A tibble: 2 x 2 word lexicon <chr> <chr> 1 roomba CUSTOM 2 2 CUSTOM
custom_stop_words <- tribble( ~word, ~lexicon, "roomba", "CUSTOM", "2", "CUSTOM" ) stop_words2 <- stop_words %>% bind_rows(custom_stop_words)
custom_stop_words <- tribble( ~word, ~lexicon, "roomba", "CUSTOM", "2", "CUSTOM" )
stop_words2 <- stop_words %>% bind_rows(custom_stop_words)
tidy_review <- review_data %>% mutate(id = row_number()) %>% select(id, date, product, stars, review) %>% unnest_tokens(word, review) %>% anti_join(stop_words2) tidy_review %>% filter(word == "roomba")
tidy_review <- review_data %>% mutate(id = row_number()) %>% select(id, date, product, stars, review) %>% unnest_tokens(word, review) %>% anti_join(stop_words2)
tidy_review %>% filter(word == "roomba")
# A tibble: 0 x 5 # … with 5 variables: id <int>, date <chr>, product <chr>, stars <dbl>, word <chr>
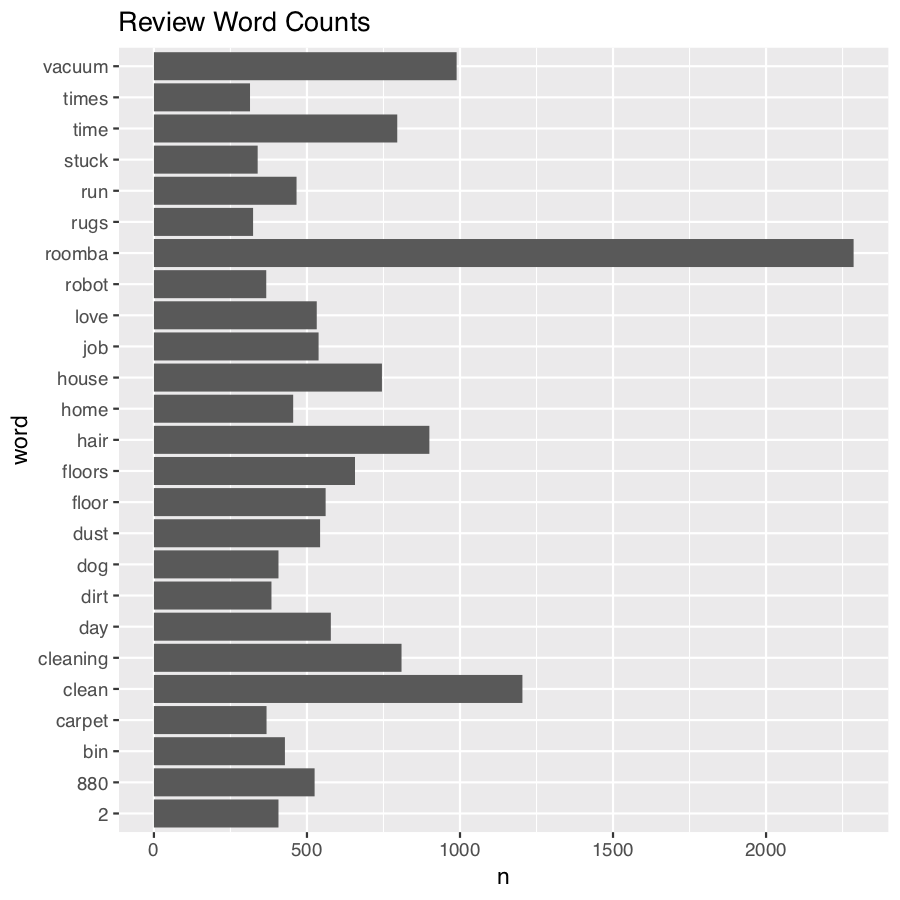
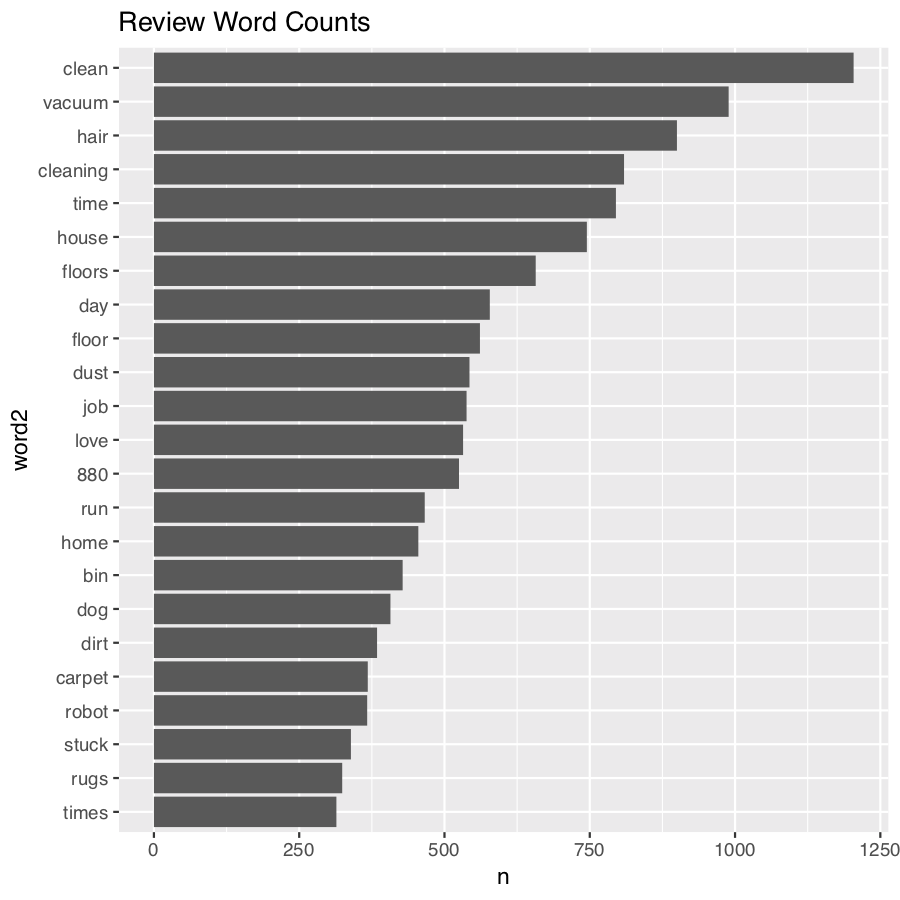
word_counts <- tidy_review %>% count(word) %>% filter(n > 300) %>% mutate(word2 = fct_reorder(word, n))
word_counts
# A tibble: 23 x 3 word n word2 <chr> <int> <fct> 1 880 525 880 2 bin 428 bin # … with 21 more rows
ggplot( word_counts, aes(x = word2, y = n) ) + geom_col() + coord_flip() + ggtitle("Review Word Counts")