Plotting word counts
Introduction to Text Analysis in R

Maham Faisal Khan
Senior Data Science Content Developer
Visualizing counts with geom_col()
Using coord_flip()
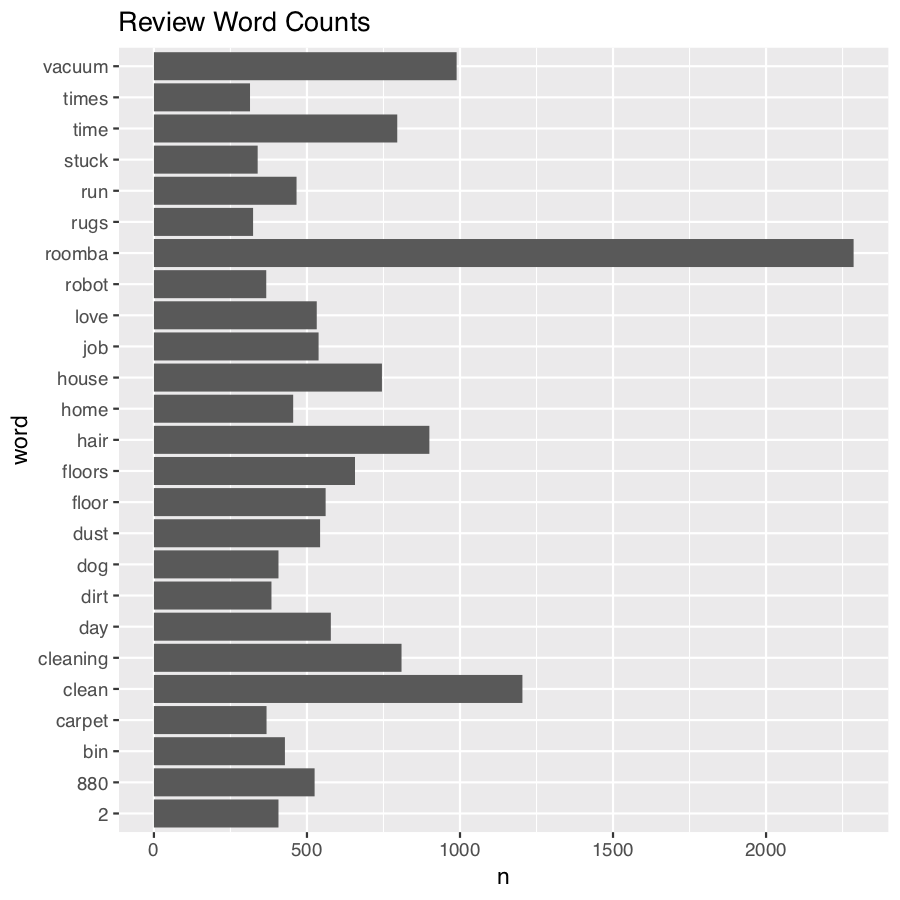
Introduction to Text Analysis in R
Maham Faisal Khan
Senior Data Science Content Developer

