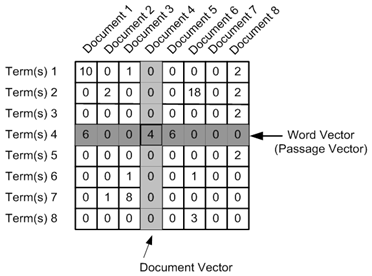
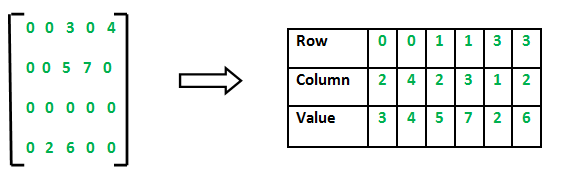
Determine the importance of the terms in a document (in TF-IDF matrix)
Cluster the TF-IDF matrix
Find top terms, documents in each cluster
Clean and tokenize data
Convert text into smaller parts called tokens, clean data for processing
from nltk.tokenize import word_tokenize
import re
def remove_noise(text, stop_words = []):
tokens = word_tokenize(text)
cleaned_tokens = []
for token in tokens:
token = re.sub('[^A-Za-z0-9]+', '', token)
if len(token) > 1 and token.lower() not in stop_words:
# Get lowercase
cleaned_tokens.append(token.lower())
return cleaned_tokens
remove_noise("It is lovely weather we are having.
I hope the weather continues.")