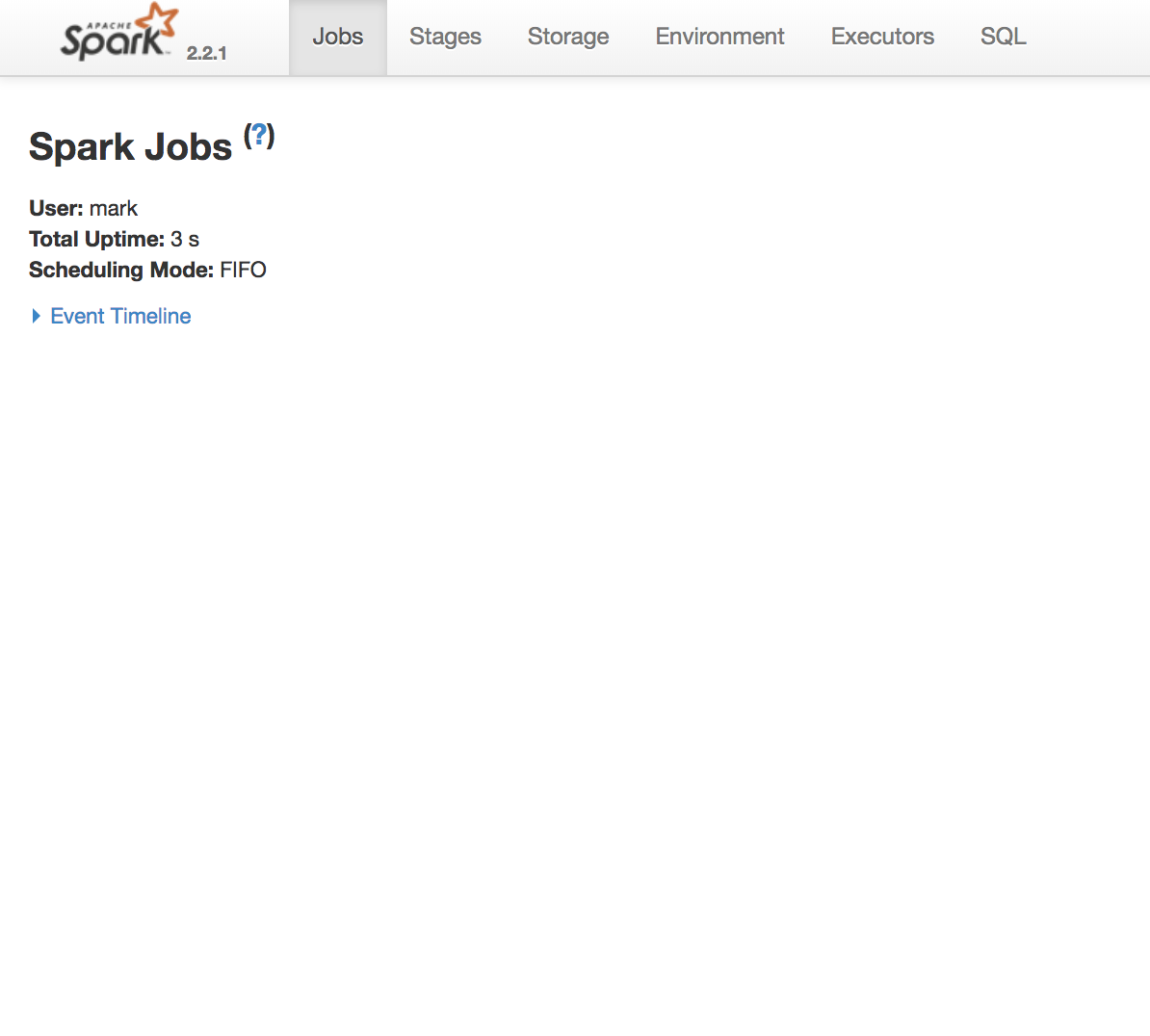
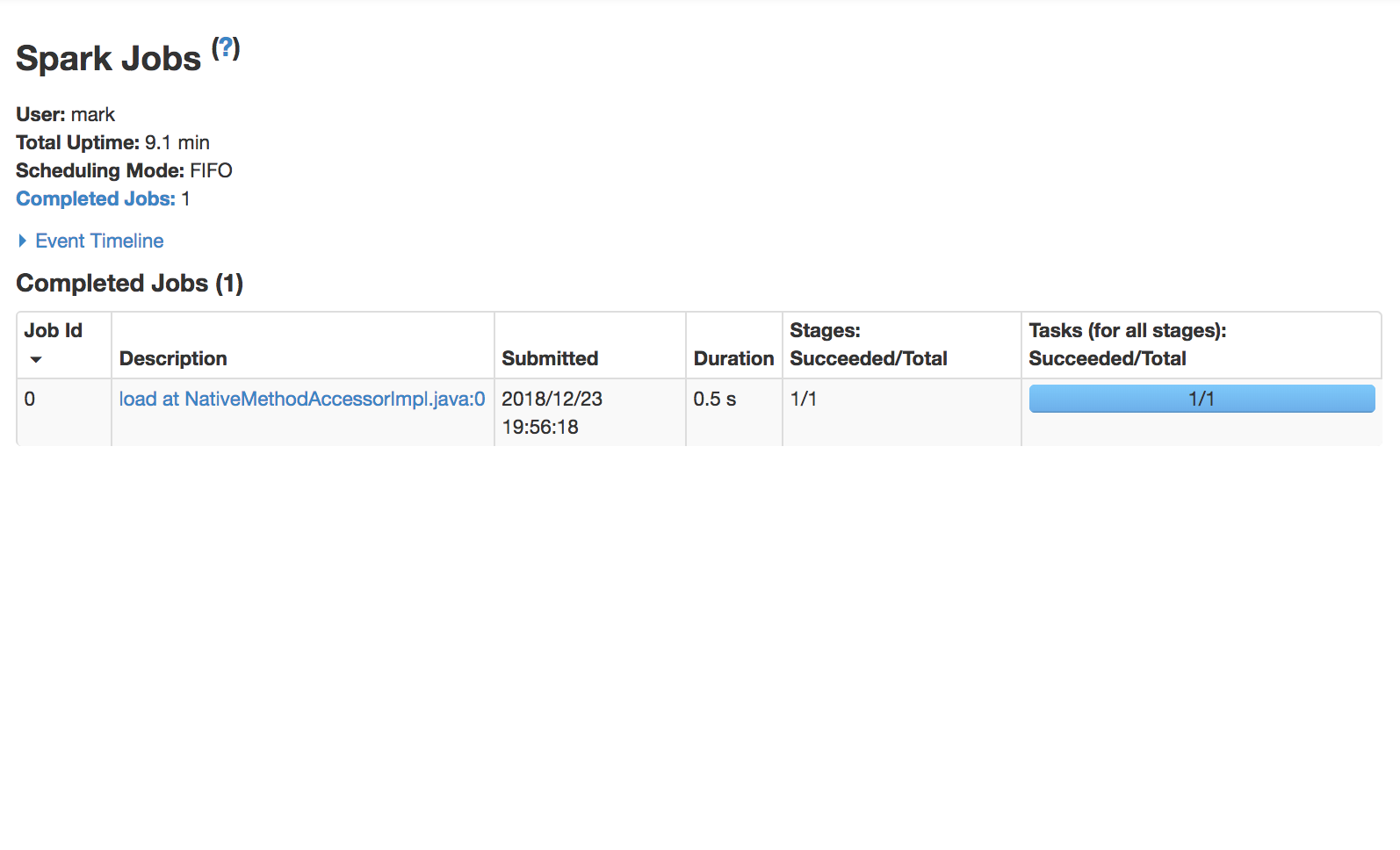
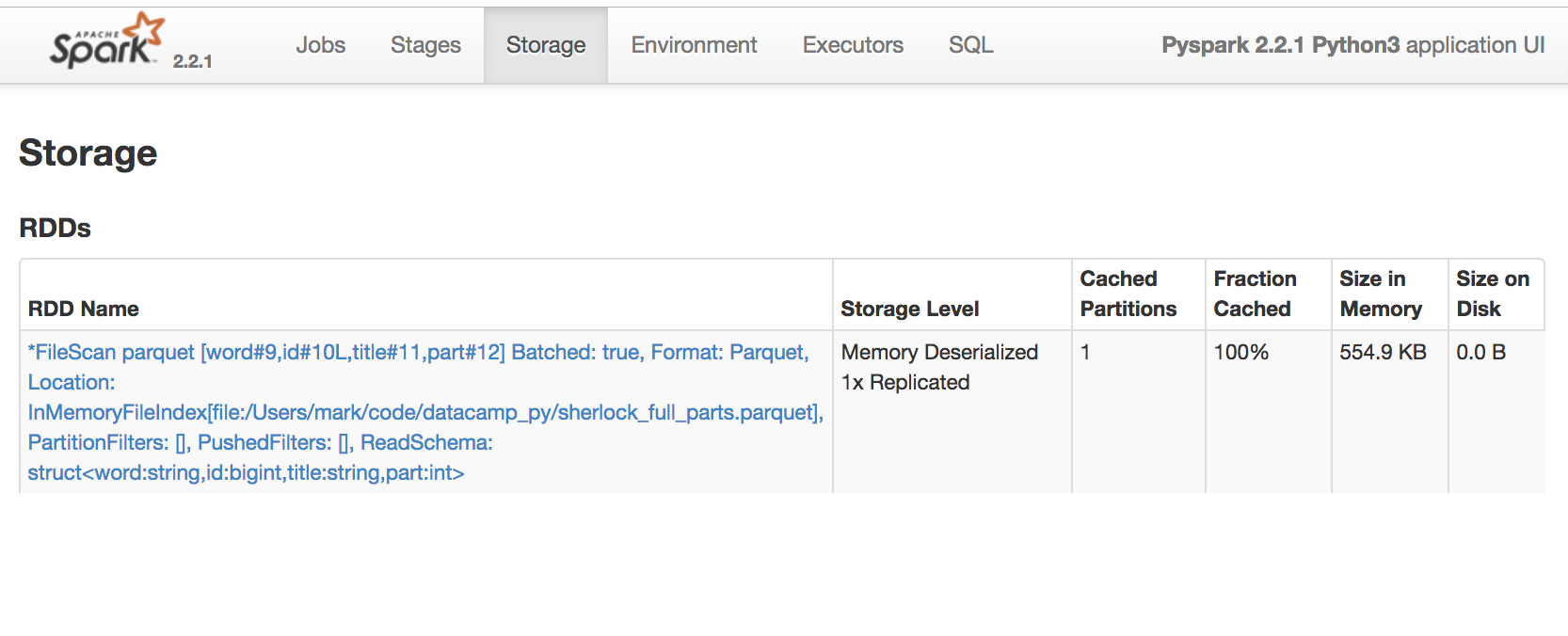
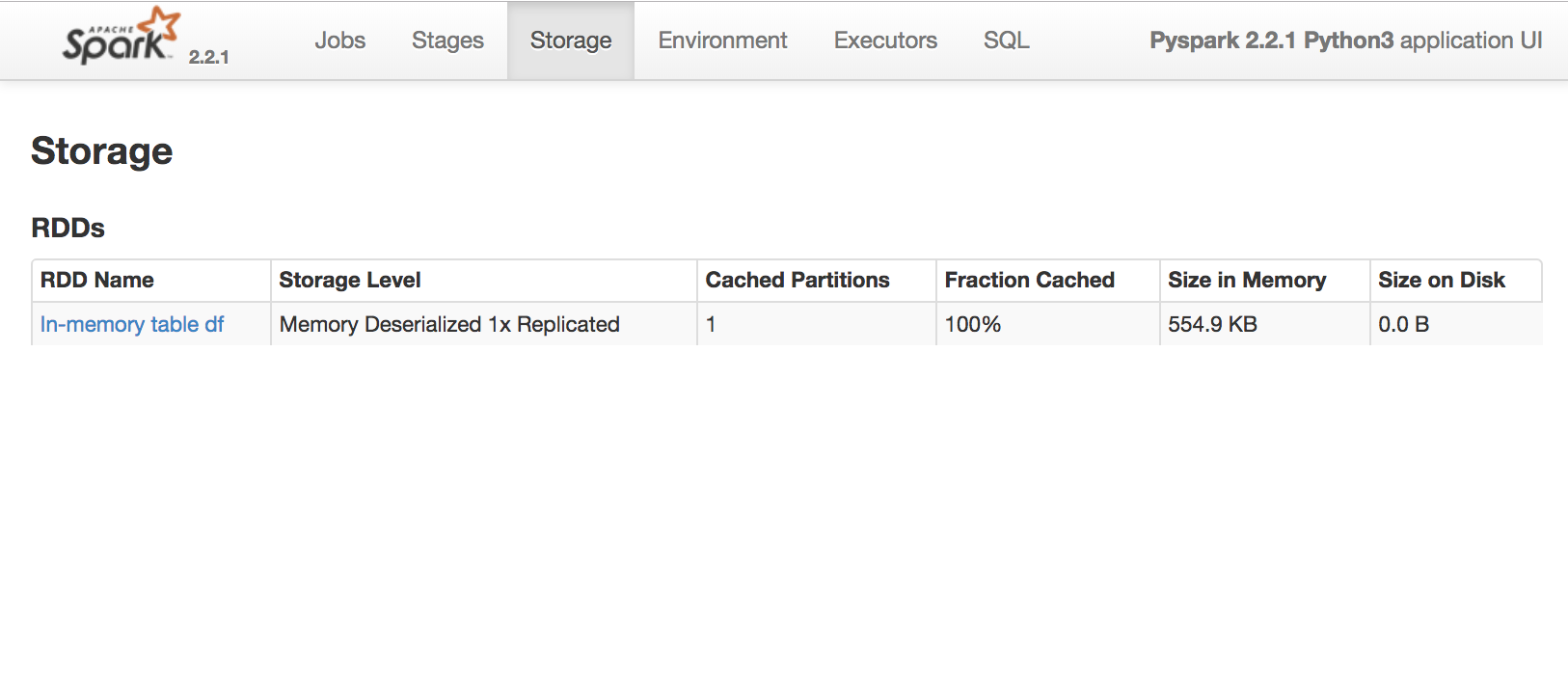
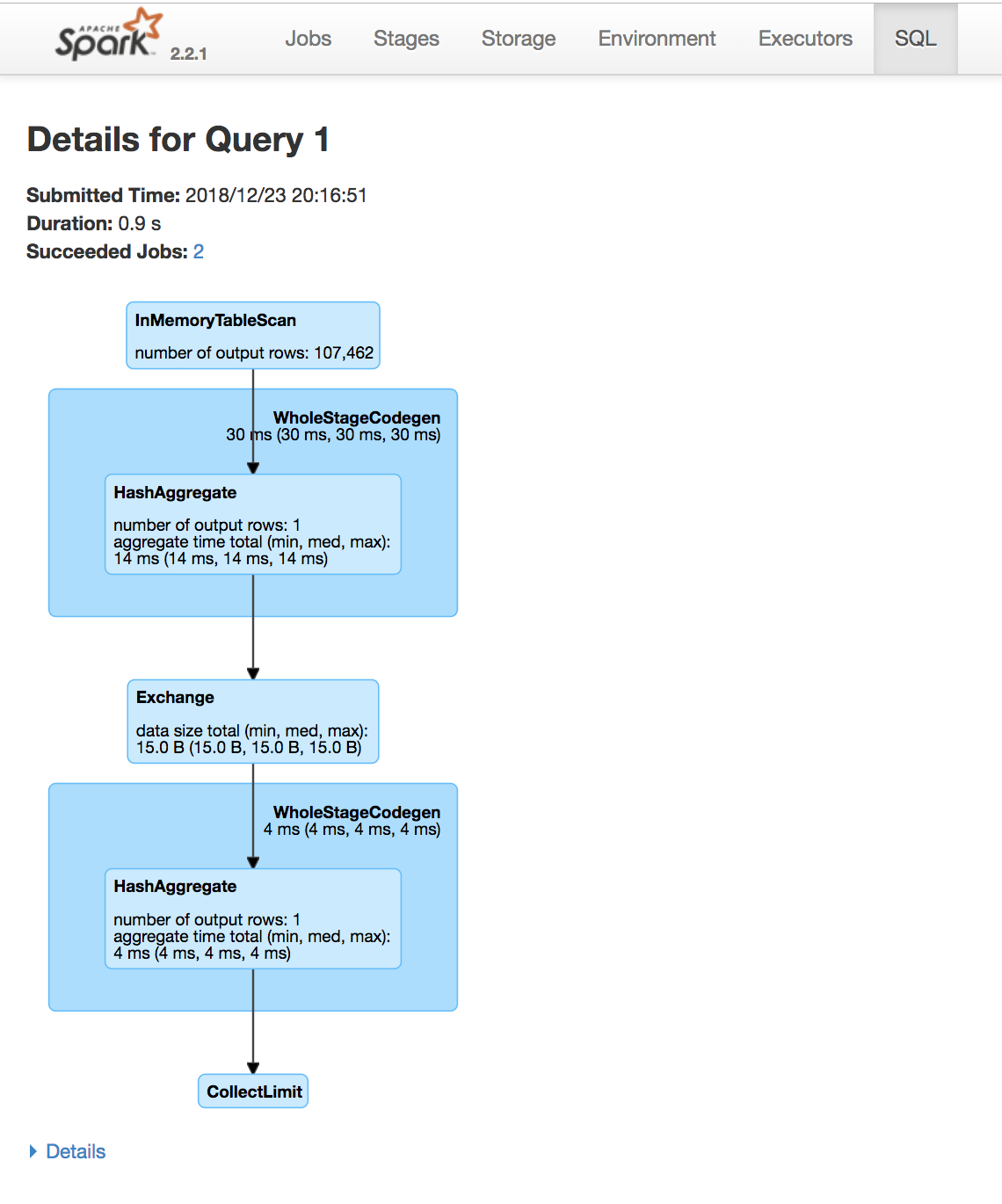
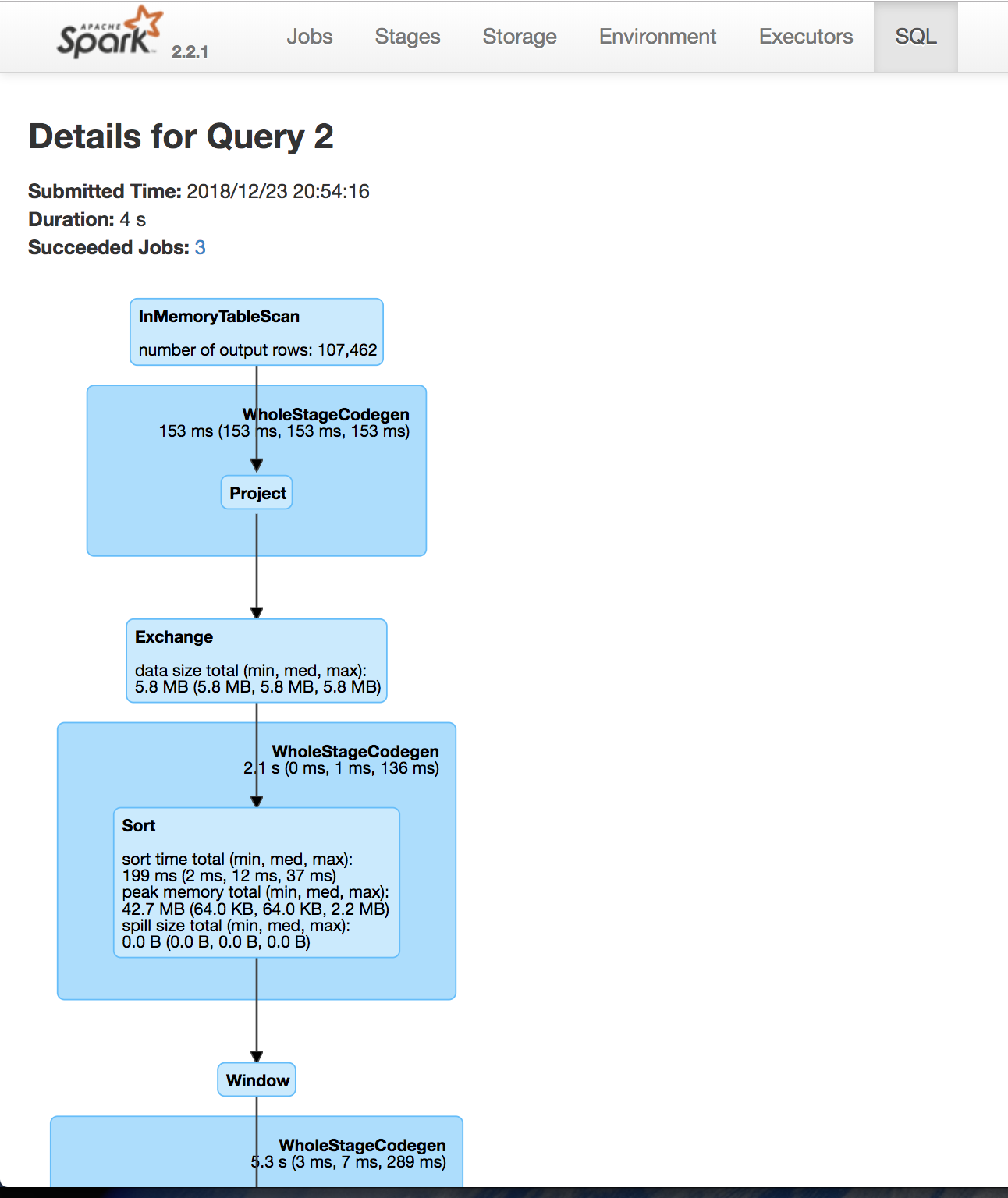
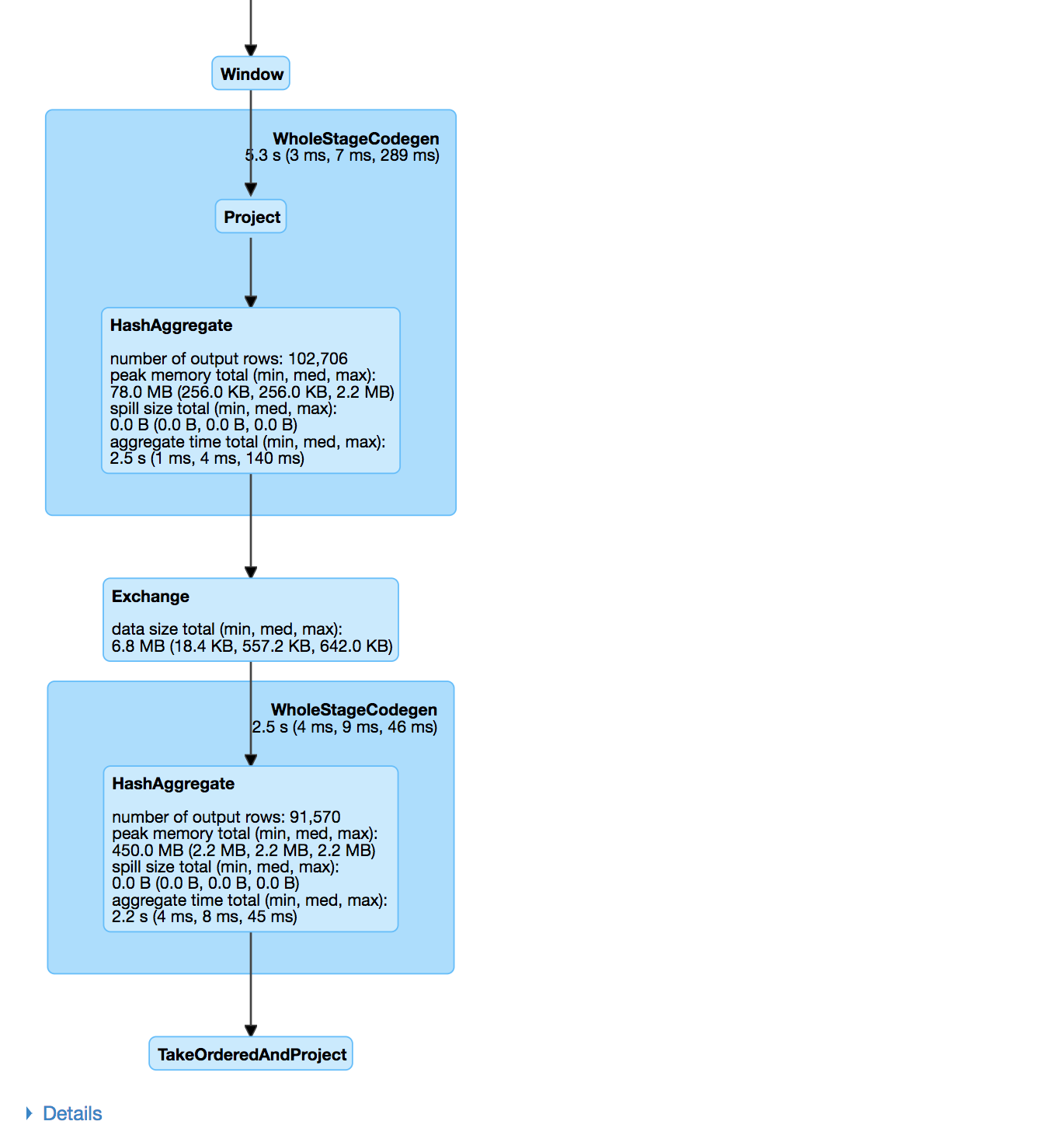
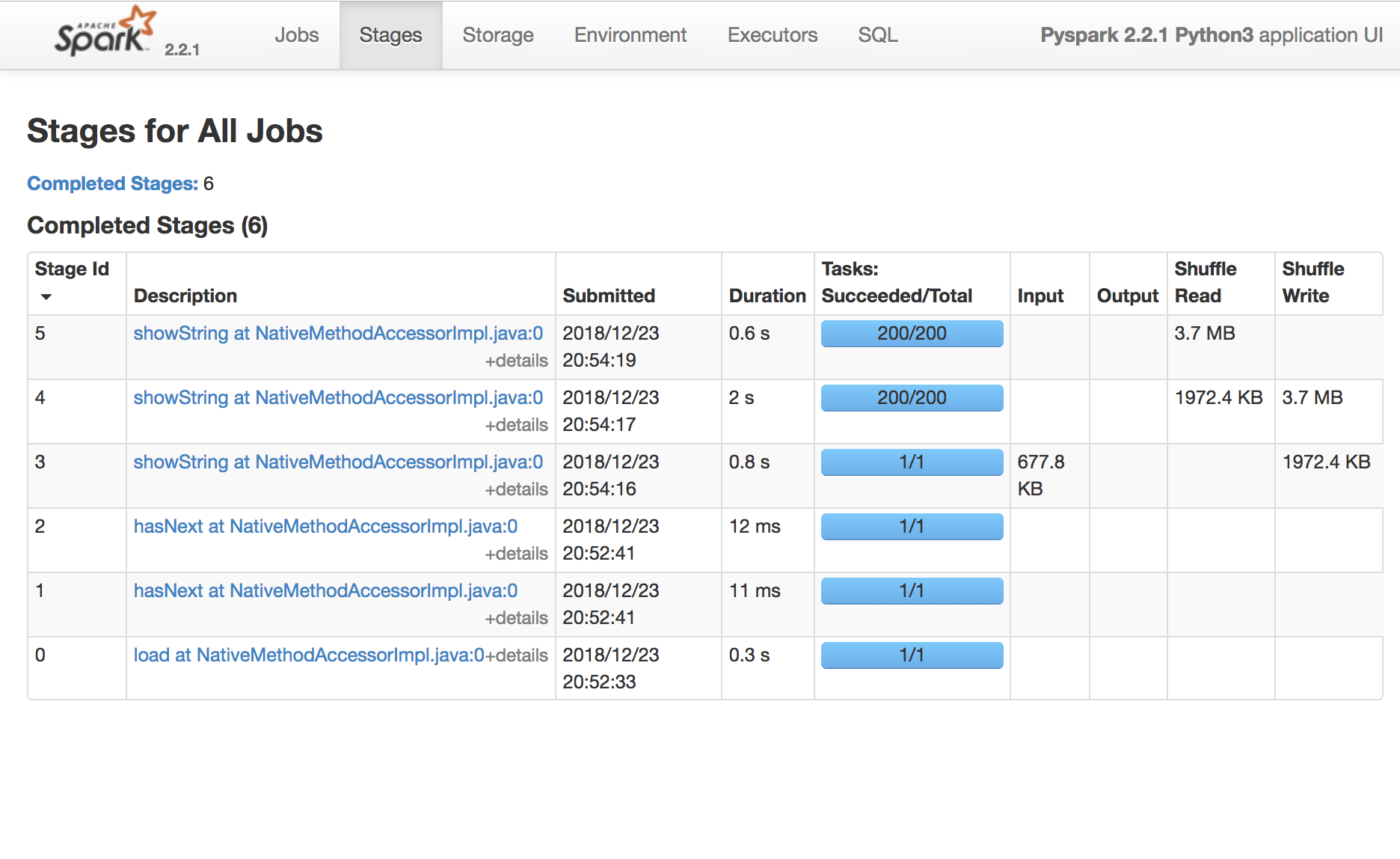
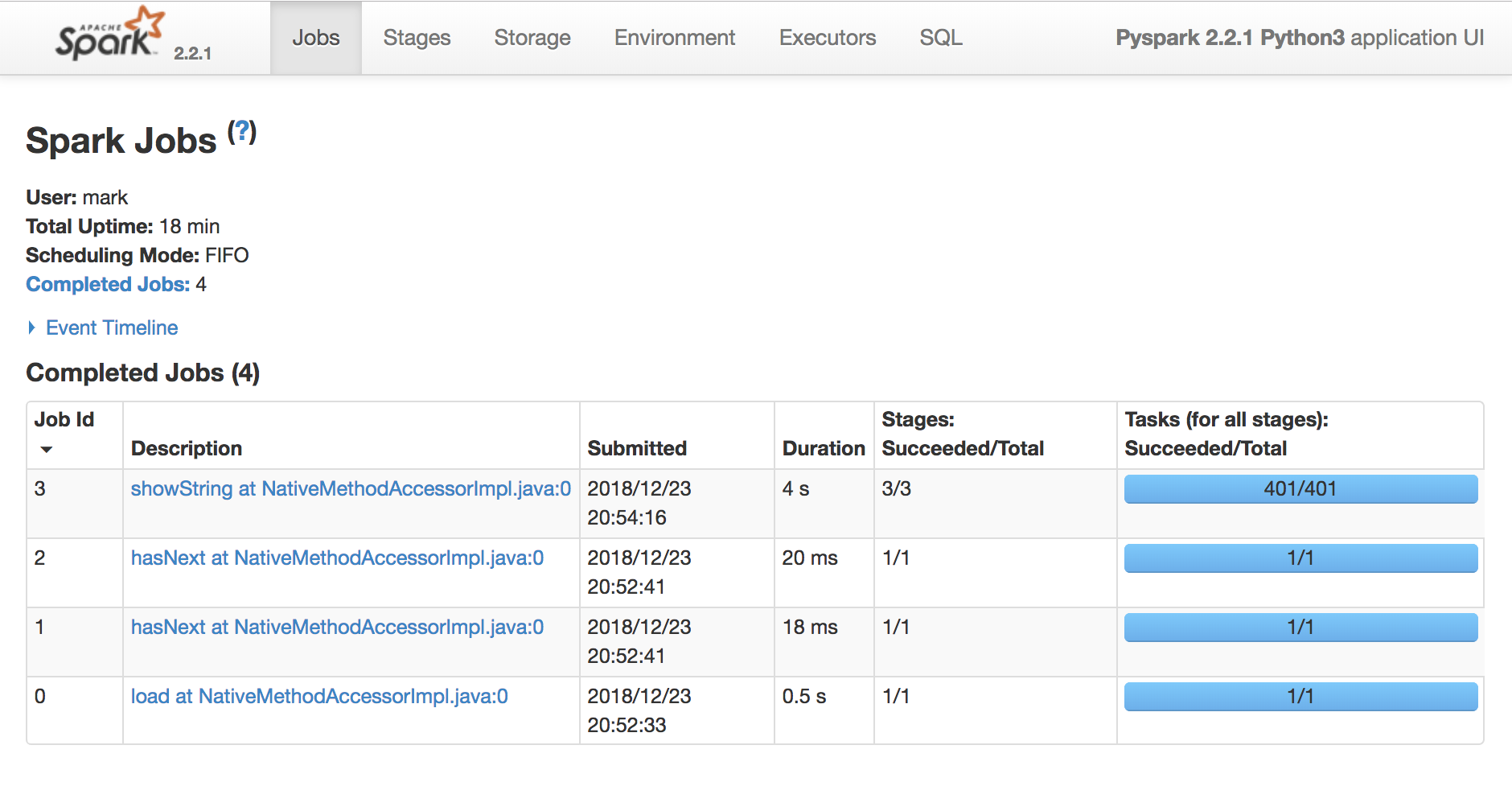
Use the Spark UI inspect execution
Spark Task is a unit of execution that runs on a single cpu
Spark Stage a group of tasks that perform the same computation in parallel, each task typically running on a different subset of the data
Spark Job is a computation triggered by an action, sliced into one or more stages.