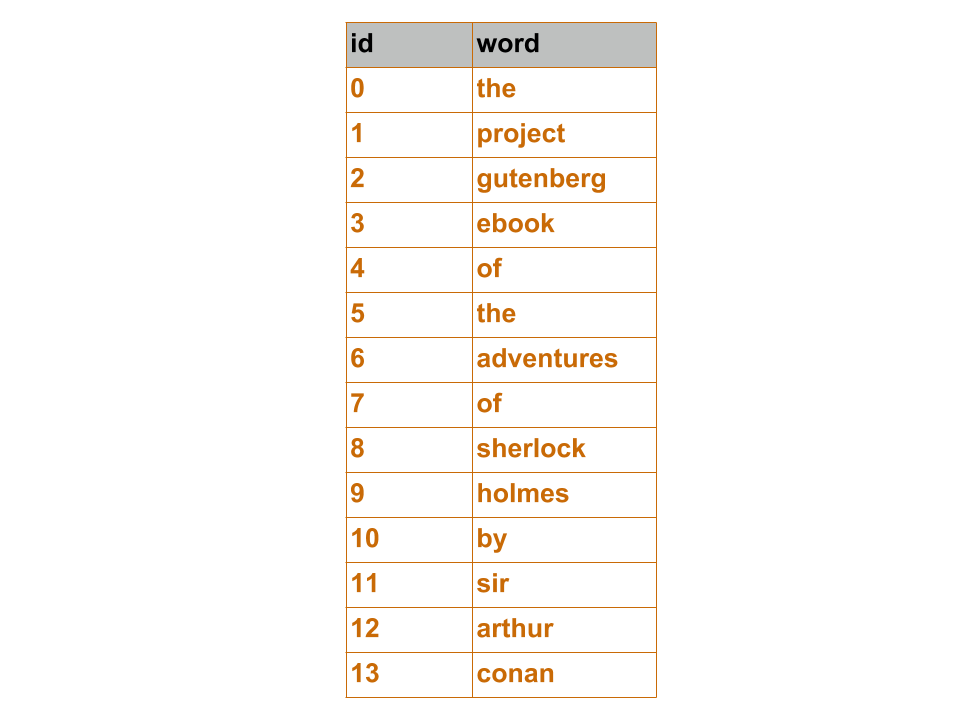
The raw text
ADVENTURE I. A SCANDAL IN BOHEMIA
I.
To Sherlock Holmes she is always the woman. I have seldom heard him mention
her under any other name. In his eyes she eclipses and predominates the whole
of her sex. It was not that he felt any emotion akin to love for Irene Adler.
All emotions, and that one particularly, were abhorrent to his cold, precise
but admirably balanced mind. He was, I take it, the most perfect reasoning
and observing machine that the world has seen, but as a lover he would have
placed himself in a false position. He never spoke of the softer passions,
save with a gibe and a sneer. They were admirable things for the observer--
excellent for drawing the veil from men's motives and actions. But for the
trained reasoner to admit such intrusions into his own delicate and finely
adjusted temperament was to introduce a distracting factor which might throw
a doubt upon all his mental results. Grit in a sensitive instrument, or a
crack in one of his own high-power lenses, would not be more disturbing than
a strong emotion in a nature such as his. And yet there was but one woman to
him, and that woman was the late Irene Adler, of dubious and questionable
memory.