Introduction to Spark SQL in Python
Mark Plutowski Phd
Data Scientist
df = spark.read.csv(filename)
df = spark.read.csv(filename, header=True)
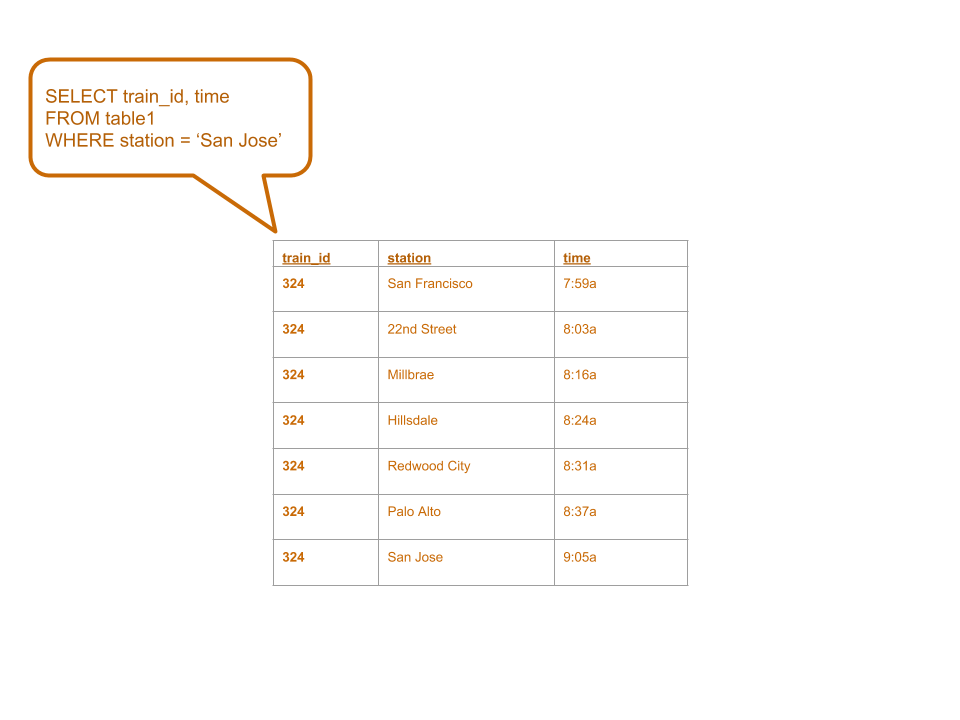
df.createOrReplaceTempView("schedule") spark.sql("SELECT * FROM schedule WHERE station = 'San Jose'") .show()
df.createOrReplaceTempView("schedule")
spark.sql("SELECT * FROM schedule WHERE station = 'San Jose'") .show()
+--------+--------+-----+ |train_id| station| time| +--------+--------+-----+ | 324|San Jose|9:05a| | 217|San Jose|6:59a| +--------+--------+-----+
result = spark.sql("SHOW COLUMNS FROM tablename")
result = spark.sql("SELECT * FROM tablename LIMIT 0")
result = spark.sql("DESCRIBE tablename")
result.show()
print(result.columns)
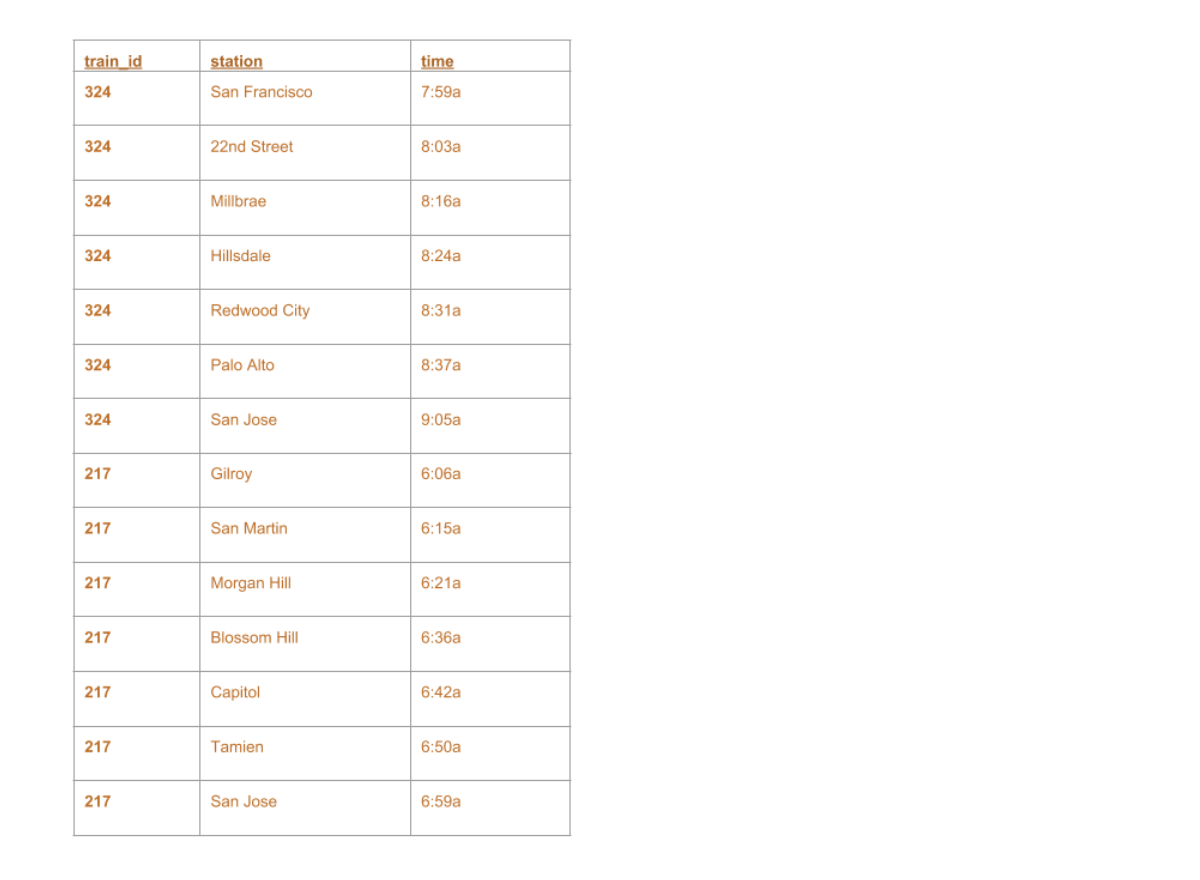
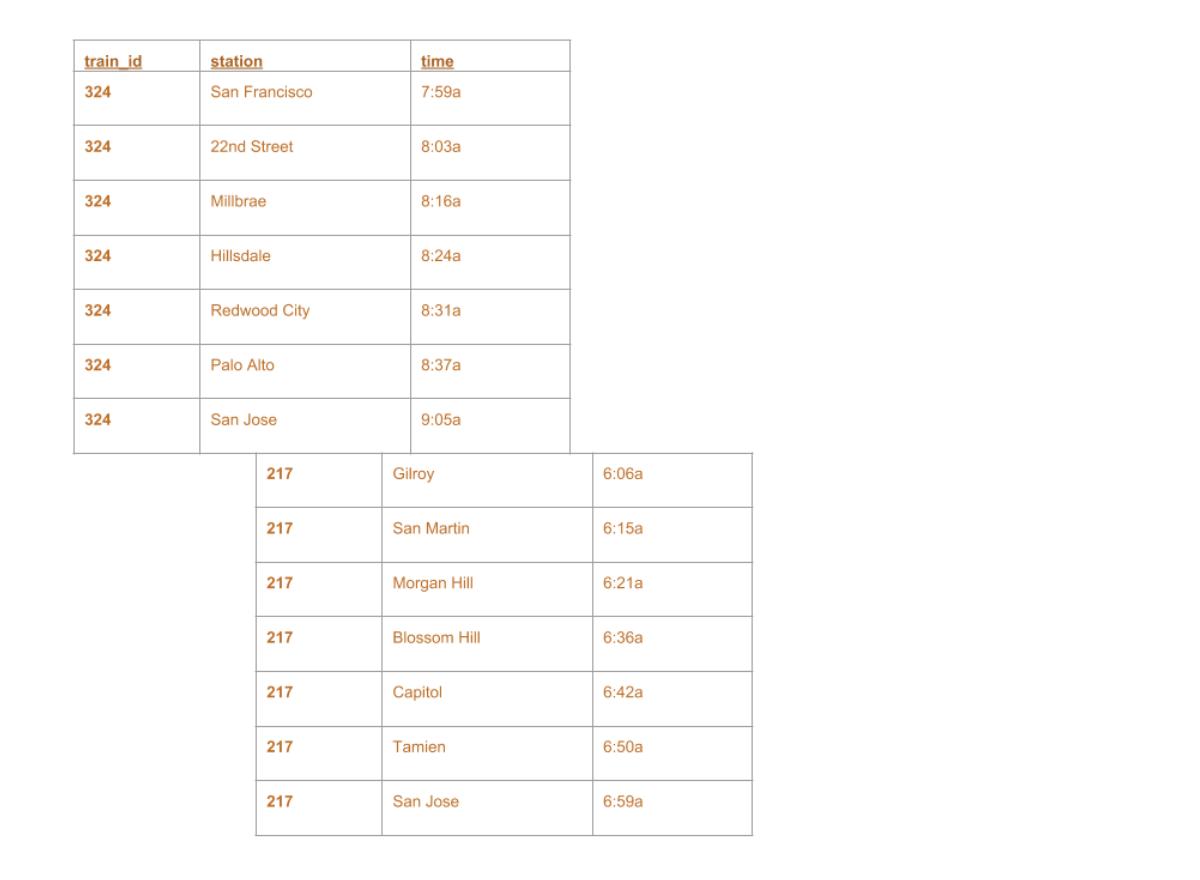
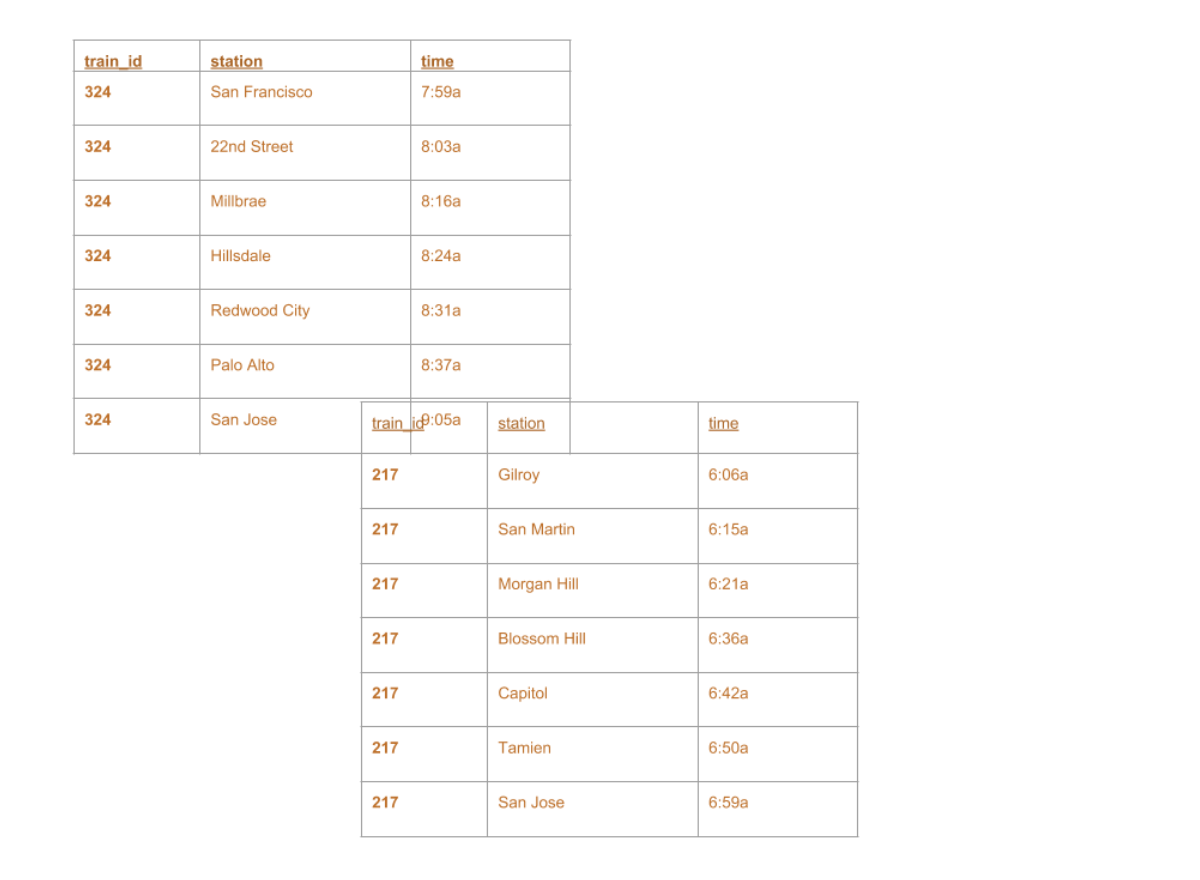
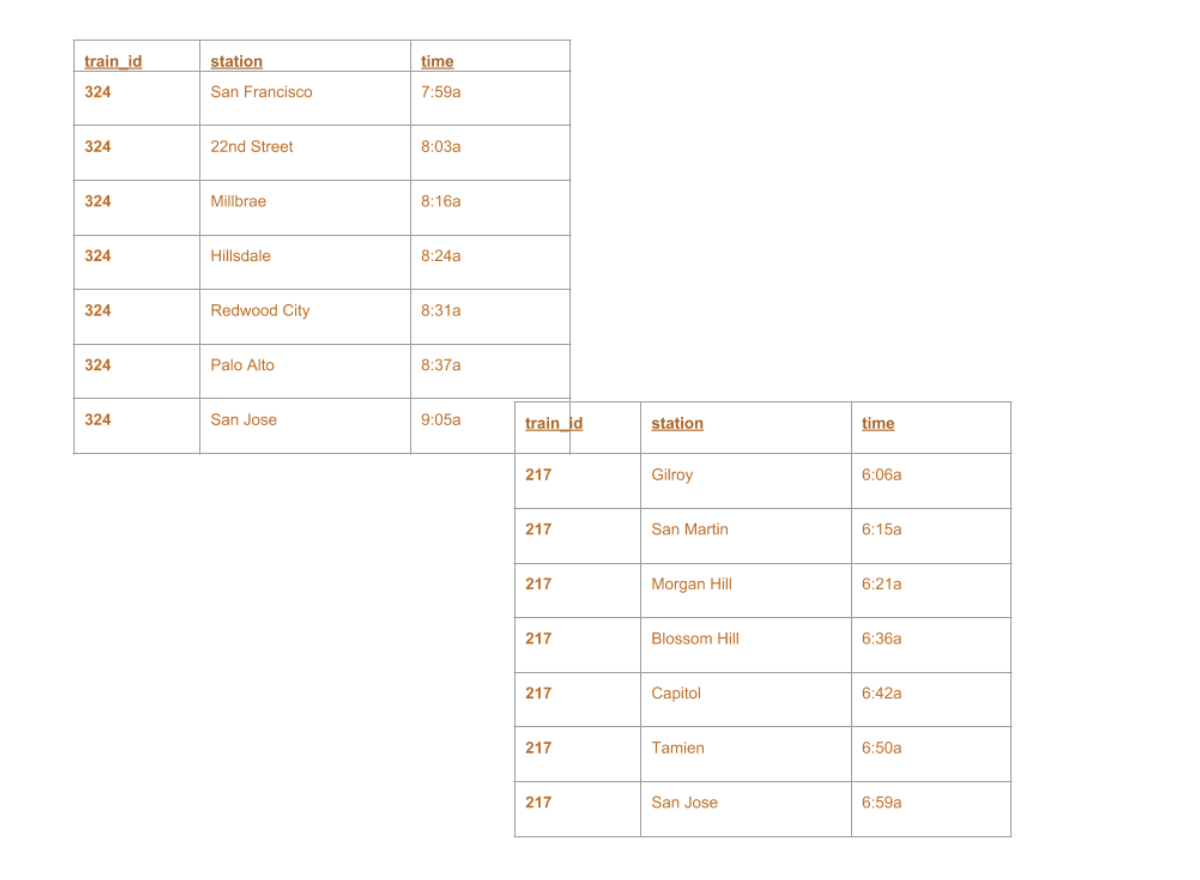
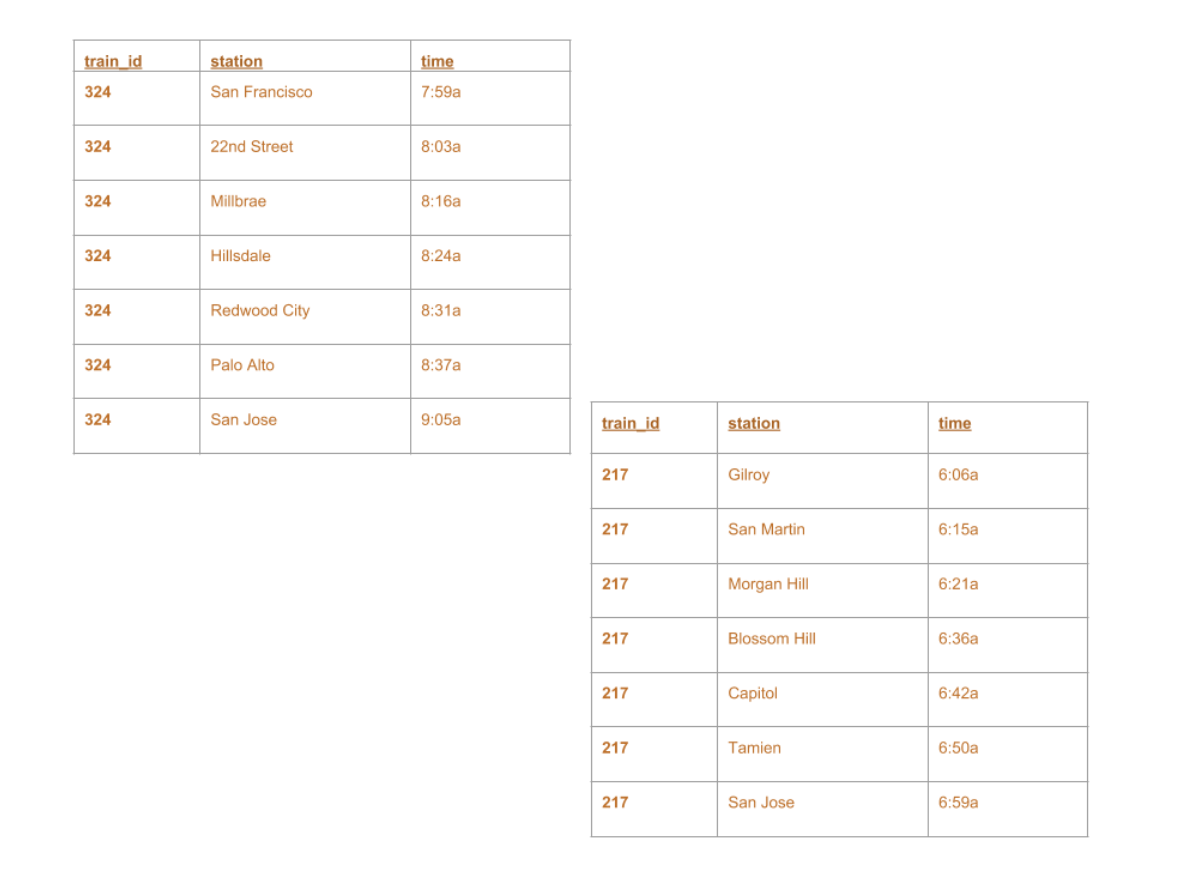
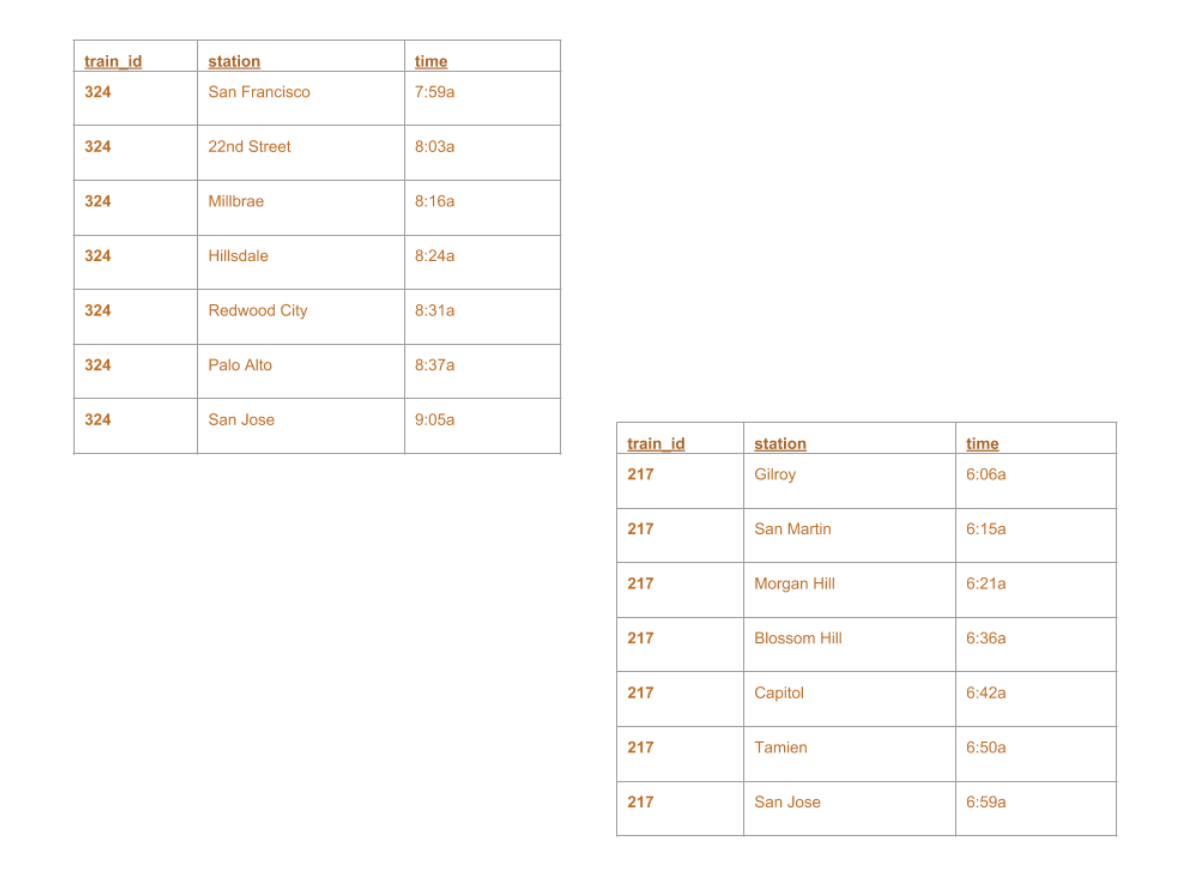
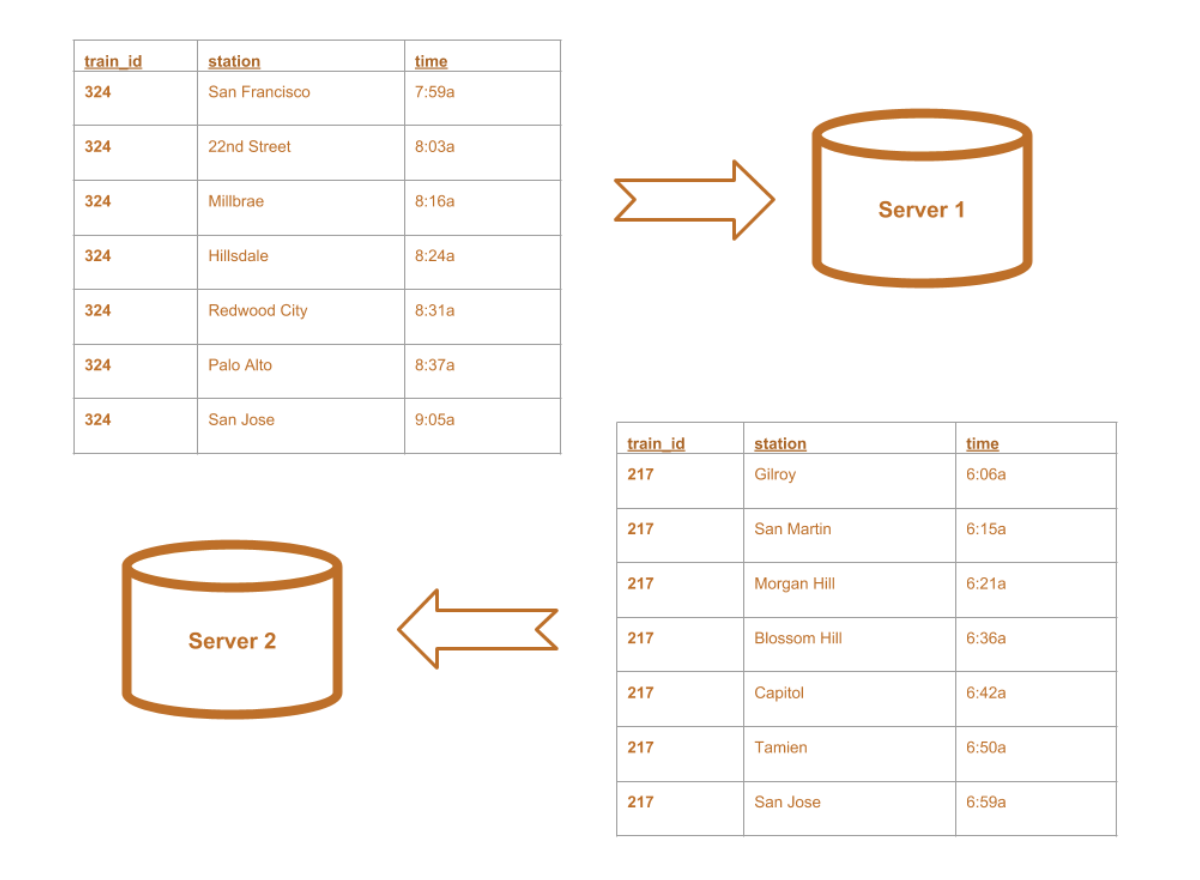
+--------+-------------+-----+ |train_id| station| time| +--------+-------------+-----+ | 324|San Francisco|7:59a| | 324| 22nd Street|8:03a| | 324| Millbrae|8:16a| | 324| Hillsdale|8:24a| | 324| Redwood City|8:31a| | 324| Palo Alto|8:37a| | 324| San Jose|9:05a| | 217| Gilroy|6:06a| | 217| San Martin|6:15a| | 217| Morgan Hill|6:21a| | 217| Blossom Hill|6:36a| | 217| Capitol|6:42a| | 217| Tamien|6:50a| | 217| San Jose|6:59a| +--------+-------------+-----+
Loads a comma-delimited file trainsched.txt into a dataframe called df :
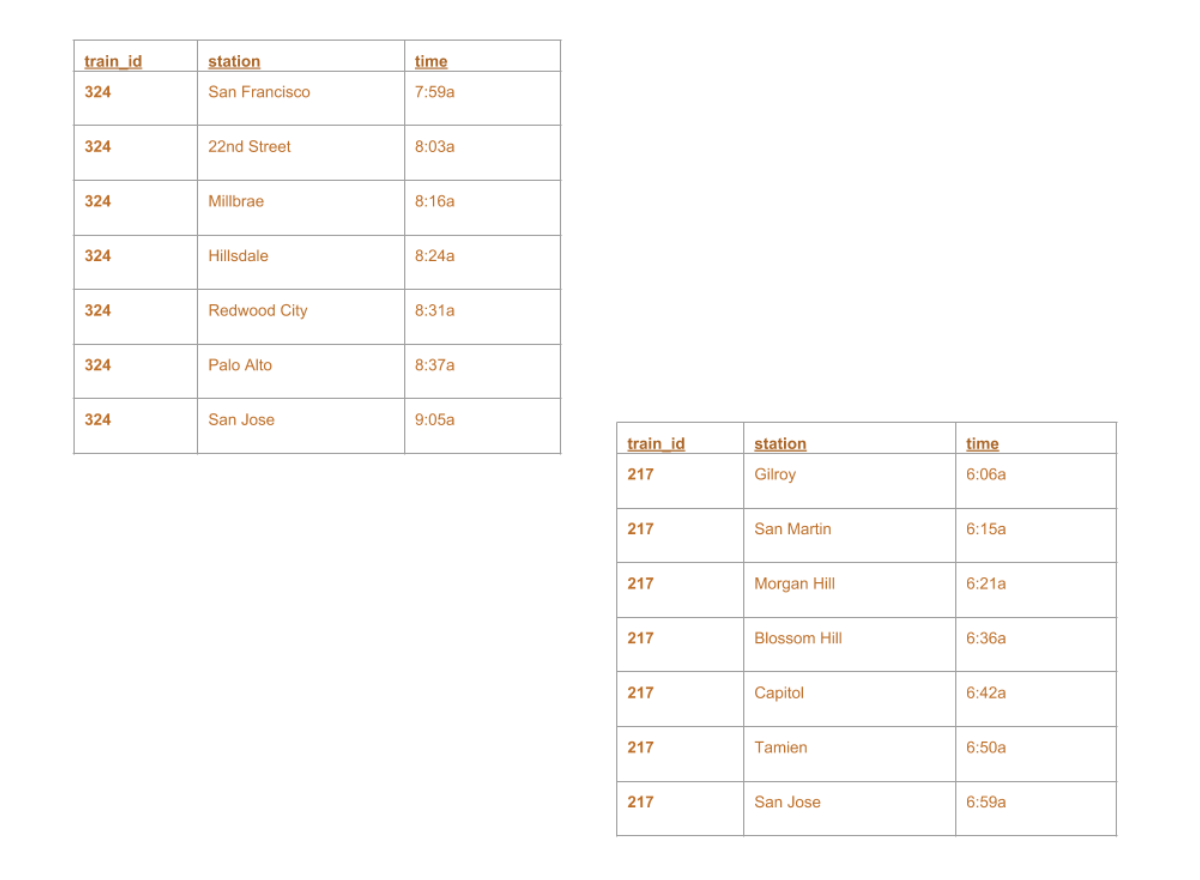
trainsched.txt
df
df = spark.read.csv("trainsched.txt", header=True)
df = spark.read.csv("trainsched.txt", header=True) df.show()
+--------+-------------+-----+ |train_id| station| time| +--------+-------------+-----+ | 324|San Francisco|7:59a| | 324| 22nd Street|8:03a| | 324| Millbrae|8:16a| | 324| Hillsdale|8:24a| | 324| Redwood City|8:31a| | ...| ...| ...| | 217| Blossom Hill|6:36a| | 217| Capitol|6:42a| | 217| Tamien|6:50a| | 217| San Jose|6:59a| +--------+-------------+-----+