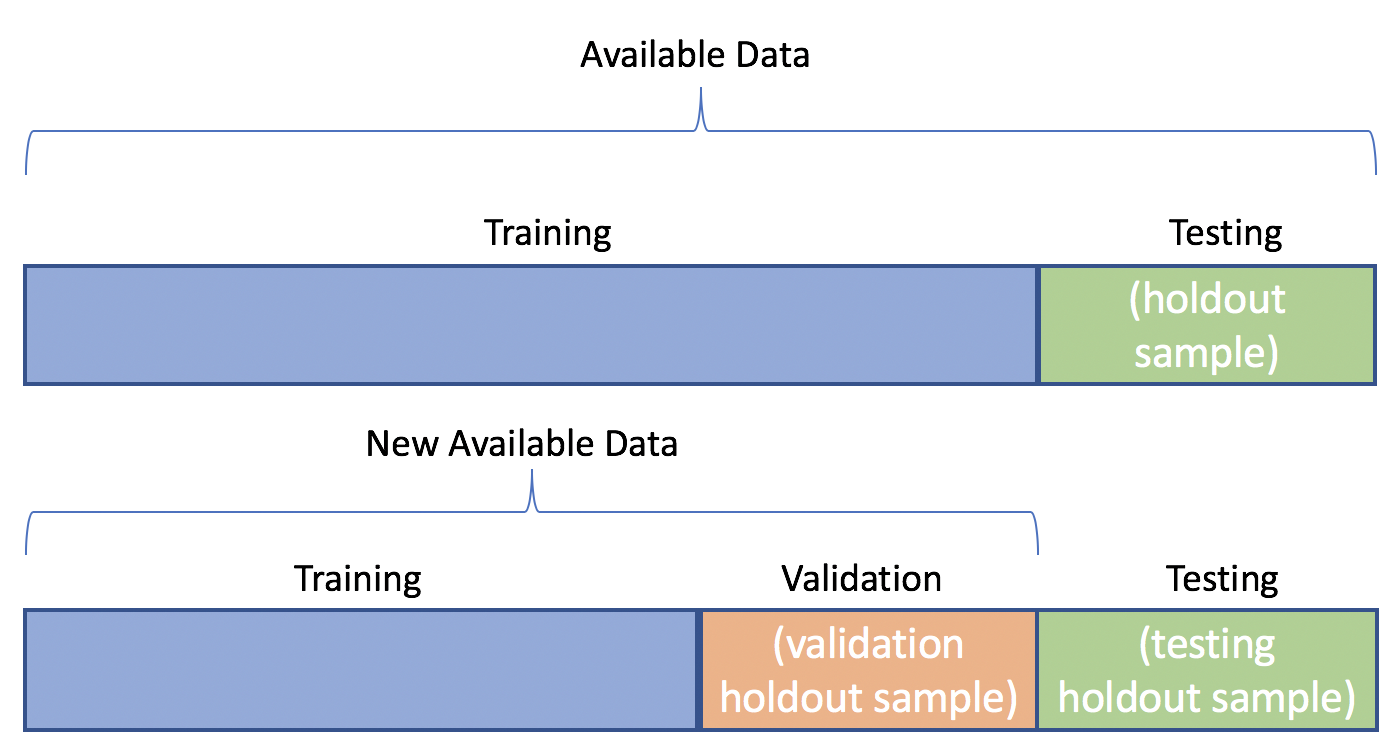
Creating train, test, and validation datasets
Model Validation in Python

Kasey Jones
Data Scientist
Traditional train/test split
- Seen data (used for training)
- Unseen data (unavailable for training)

Model Validation in Python
Kasey Jones
Data Scientist

