Introducing Grid Search
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
Automating 2 Hyperparameters
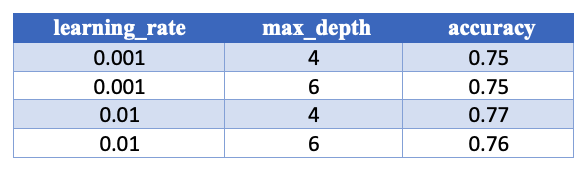
We can put these results into a DataFrame as well and print out:
results_df = pd.DataFrame(results_list, columns=['learning_rate', 'max_depth', 'accuracy'])
print(results_df)
Introducing Grid Search
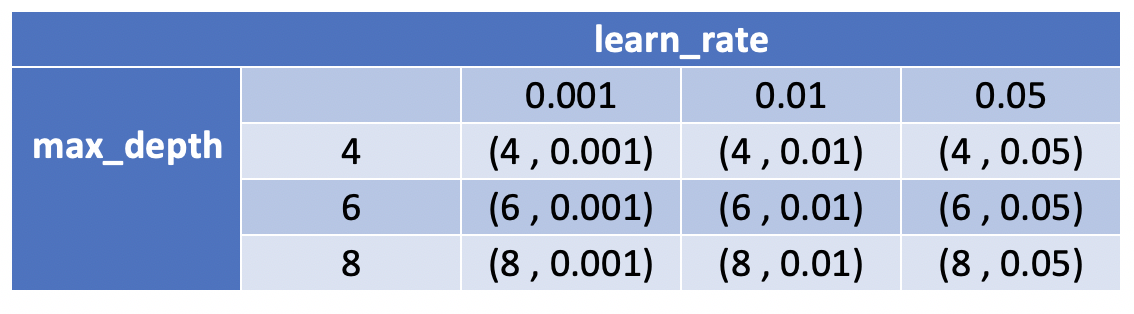
Let's create a grid:
- Down the left all values of max_depth
- Across the top all values of learning_rate
Introducing Grid Search
Working through each cell on the grid:
(4,0.001) is equivalent to making an estimator like so:
GradientBoostingClassifier(max_depth=4, learning_rate=0.001)

