Introducing Random Search
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
A probability trick
A grid search:
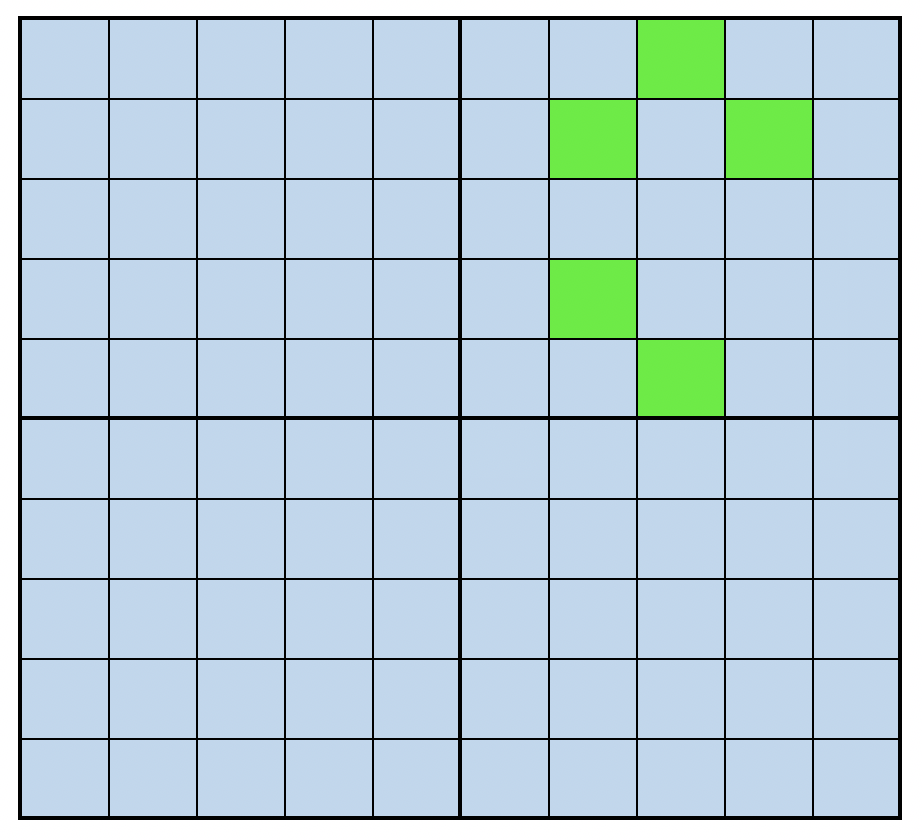
How many models must we run to have a 95% chance of getting one of the green squares?
Our best models:
Visualizing a Random Search
We can also visualize the random search coverage by plotting the hyperparameter choices on an X and Y axis.
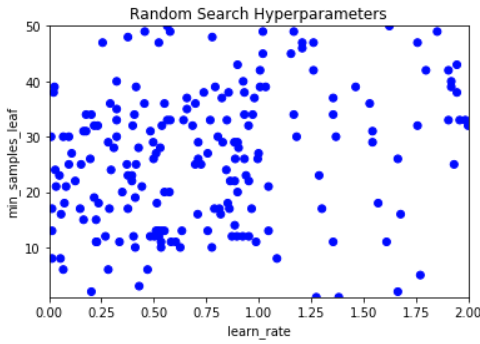
Notice how this has a wide range of the scatter but not deep coverage?

