Understanding a grid search output
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
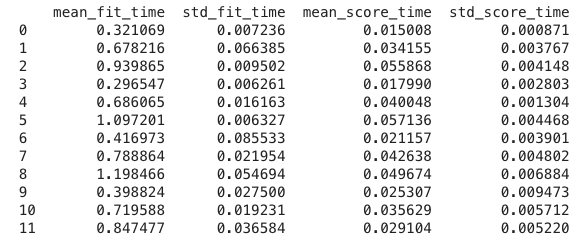
The .cv_results_ 'time' columns
The time columns refer to the time it took to fit (and score) the model.
Remember how we did a 5-fold cross-validation? This ran 5 times and stored the average and standard deviation of the times it took in seconds.
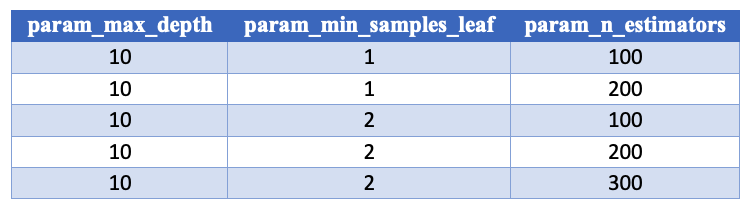
The .cv_results_ 'param_' columns
The param_ columns store the parameters it tested on that row, one column per parameter
The .cv_results_ 'param' column
The params column contains dictionary of all the parameters:
pd.set_option("display.max_colwidth", -1)
print(cv_results_df.loc[:, "params"])

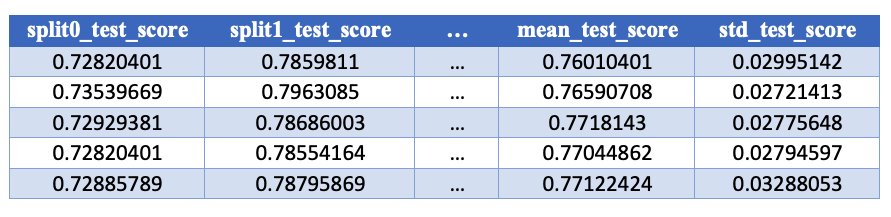
The .cv_results_ 'test_score' columns
The test_score columns contain the scores on our test set for each of our cross-folds as well as some summary statistics:
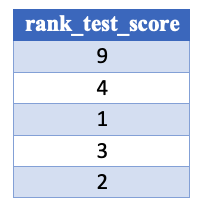
The .cv_results_ 'rank_test_score' column
The rank column, ordering the mean_test_score from best to worst:
Extracting the best row
We can select the best grid square easily from cv_results_ using the rank_test_score column
best_row = cv_results_df[cv_results_df["rank_test_score"] == 1]
print(best_row)

The best_estimator_ property
print(grid_rf_class.best_estimator_)


