Grid Search with Scikit Learn
Hyperparameter Tuning in Python

Alex Scriven
Data Scientist
GridSearchCV Object
Introducing a GridSearchCV object:
sklearn.model_selection.GridSearchCV(
estimator,
param_grid, scoring=None, fit_params=None,
n_jobs=None, refit=True, cv='warn',
verbose=0, pre_dispatch='2*n_jobs',
error_score='raise-deprecating',
return_train_score='warn')
Steps in a Grid Search
Steps in a Grid Search:
- An algorithm to tune the hyperparameters. (Sometimes called an 'estimator')
- Defining which hyperparameters we will tune
- Defining a range of values for each hyperparameter
- Setting a cross-validation scheme; and
- Define a score function so we can decide which square on our grid was 'the best'.
- Include extra useful information or functions
GridSearchCV Object Inputs
The important inputs are:
estimatorparam_gridcvscoringrefitn_jobsreturn_train_score
GridSearchCV 'estimator'
The estimator input:
- Essentially our algorithm
- You have already worked with KNN, Random Forest, GBM, Logistic Regression
Remember:
- Only one estimator per GridSearchCV object
GridSearchCV 'param_grid'
The param_grid input:
- Setting which hyperparameters and values to test
Rather than a list:
max_depth_list = [2, 4, 6, 8]
min_samples_leaf_list = [1, 2, 4, 6]
This would be:
param_grid = {'max_depth': [2, 4, 6, 8],
'min_samples_leaf': [1, 2, 4, 6]}
GridSearchCV 'param_grid'
The param_grid input:
Remember: The keys in your param_grid dictionary must be valid hyperparameters.
For example, for a Logistic regression estimator:
# Incorrect
param_grid = {'C': [0.1,0.2,0.5],
'best_choice': [10,20,50]}
ValueError: Invalid parameter best_choice for estimator LogisticRegression
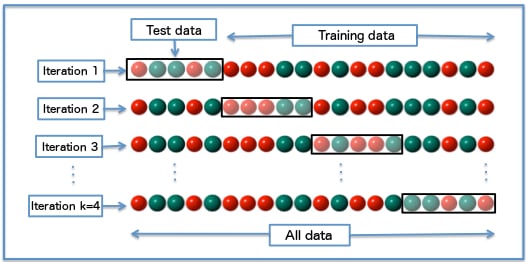
GridSearchCV 'cv'
The cv input:
- Choice of how to undertake cross-validation
- Using an integer undertakes k-fold cross validation where 5 or 10 is usually standard
GridSearchCV 'scoring'
The scoring input:
- Which score to use to choose the best grid square (model)
- Use your own or Scikit Learn's
metricsmodule
You can check all the built in scoring functions this way:
from sklearn import metrics
sorted(metrics.SCORERS.keys())
GridSearchCV 'refit'
The refit input:
- Fits the best hyperparameters to the training data
- Allows the
GridSearchCVobject to be used as an estimator (for prediction) - A very handy option!
GridSearchCV 'n_jobs'
The n_jobs input:
- Assists with parallel execution
- Allows multiple models to be created at the same time, rather than one after the other
Some handy code:
import os
print(os.cpu_count())
Careful using all your cores for modelling if you want to do other work!
GridSearchCV 'return_train_score'
The return_train_score input:
- Logs statistics about the training runs that were undertaken
- Useful for analyzing bias-variance trade-off but adds computational expense.
- Does not assist in picking the best model, only for analysis purposes
Building a GridSearchCV object
Building our own GridSearchCV Object:
# Create the grid param_grid = {'max_depth': [2, 4, 6, 8], 'min_samples_leaf': [1, 2, 4, 6]}#Get a base classifier with some set parameters. rf_class = RandomForestClassifier(criterion='entropy', max_features='auto')
Building a GridSearchCv Object
Putting the pieces together:
grid_rf_class = GridSearchCV(
estimator = rf_class,
param_grid = parameter_grid,
scoring='accuracy',
n_jobs=4,
cv = 10,
refit=True,
return_train_score=True)
Using a GridSearchCV Object
Because we set refit to True we can directly use the object:
#Fit the object to our data
grid_rf_class.fit(X_train, y_train)
# Make predictions
grid_rf_class.predict(X_test)
Let's practice!
Hyperparameter Tuning in Python

