Plotting a histogram
Statistical Thinking in Python (Part 1)

Justin Bois
Teaching Professor at the California Institute of Technology
2008 US swing state election results
Data retrieved from Data.gov (https://www.data.gov/)
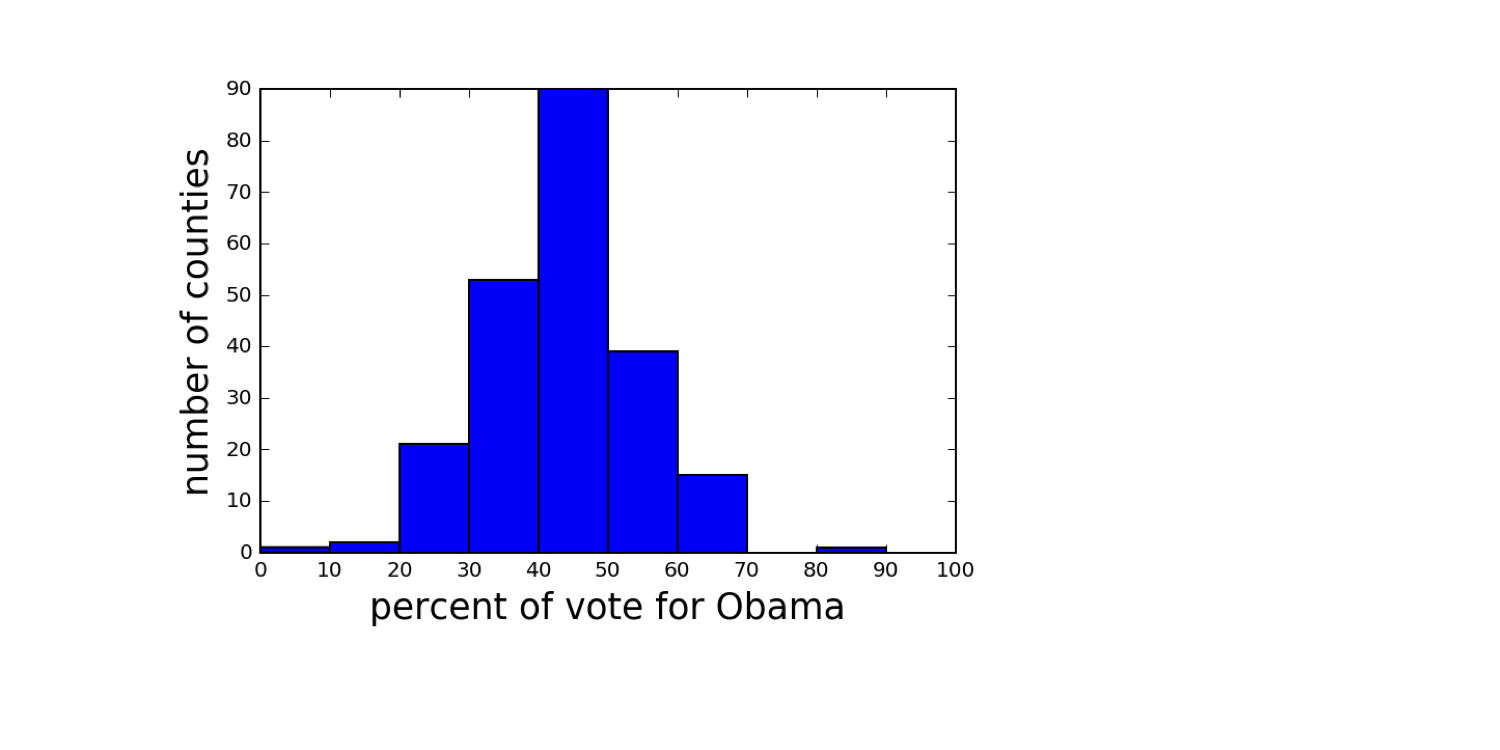
2008 US swing state election results
Data retrieved from Data.gov (https://www.data.gov/)
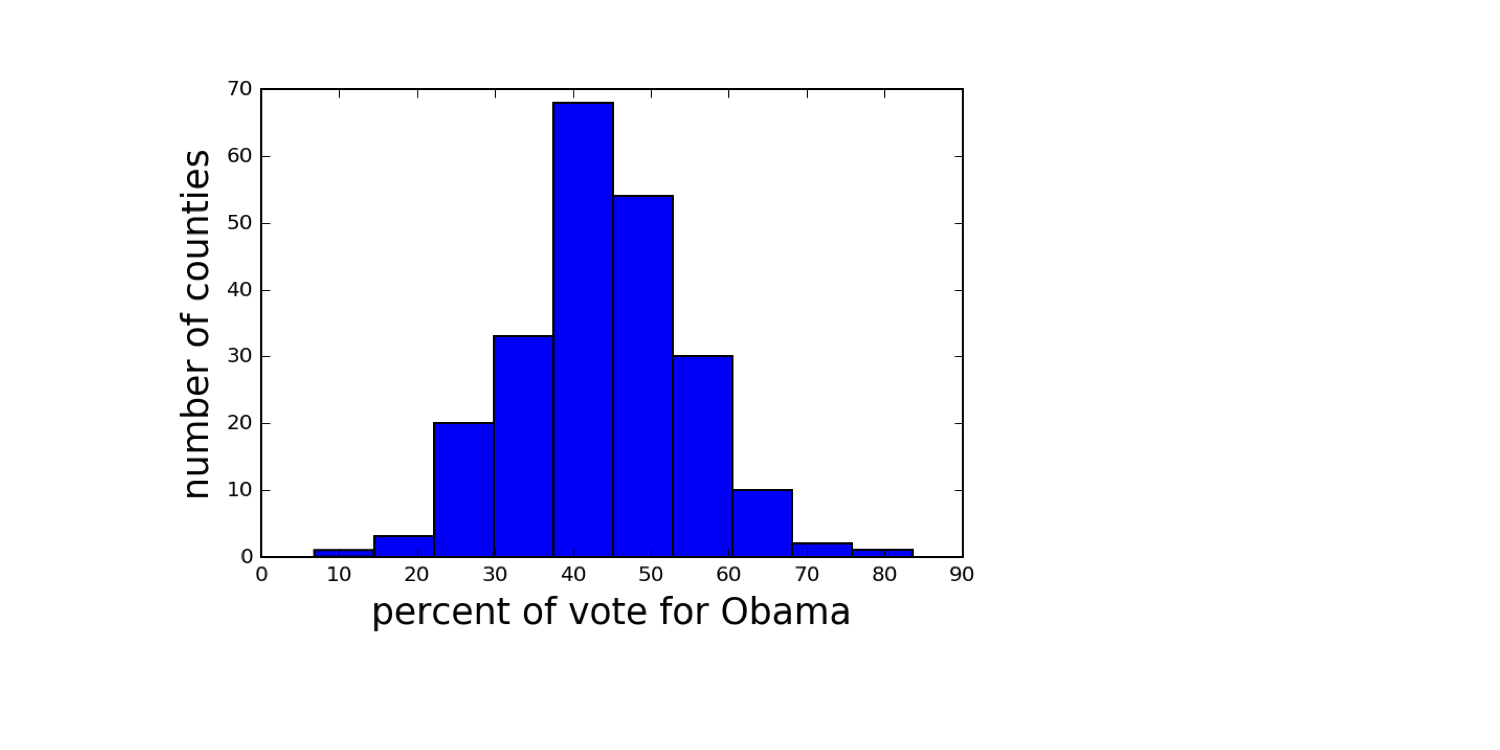
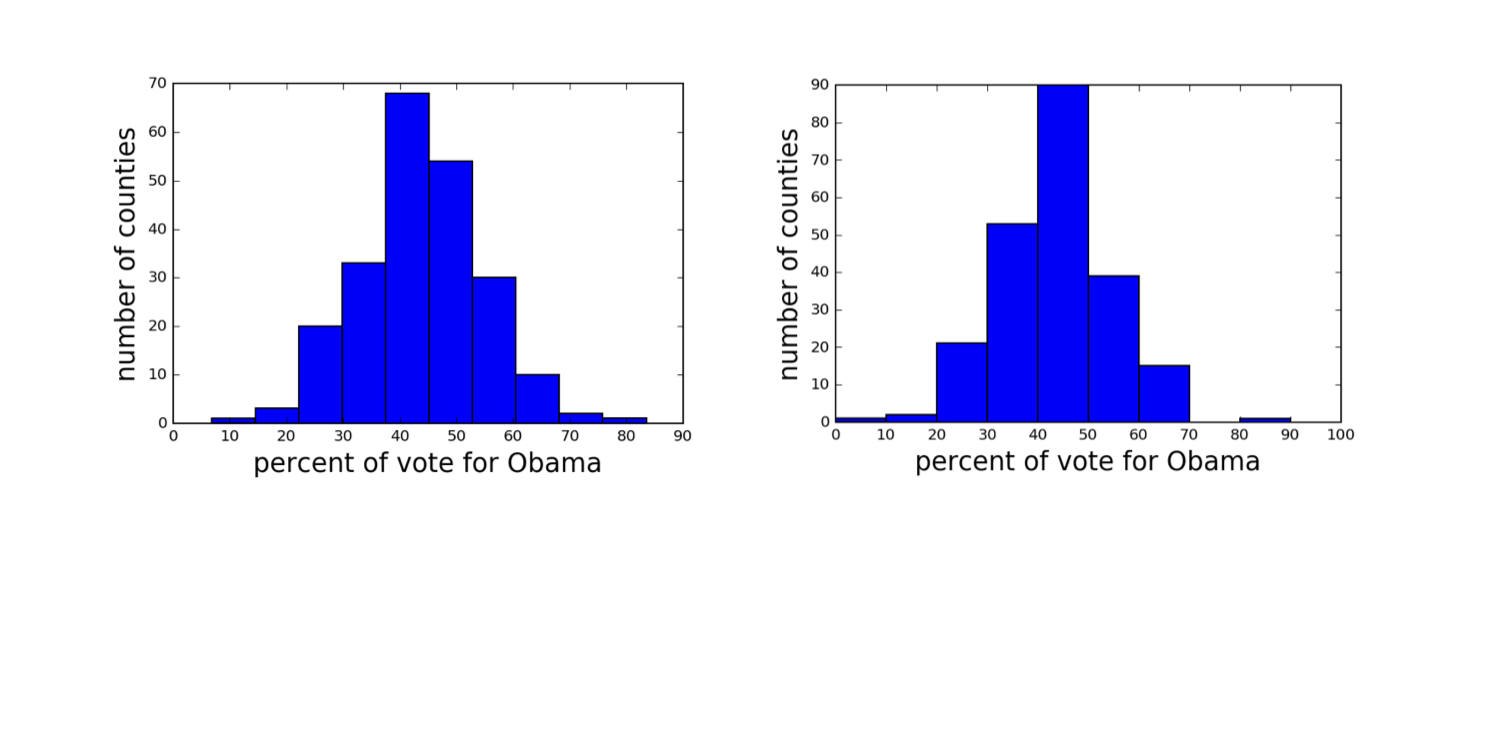
Histograms with different binning
Data retrieved from Data.gov (https://www.data.gov/)
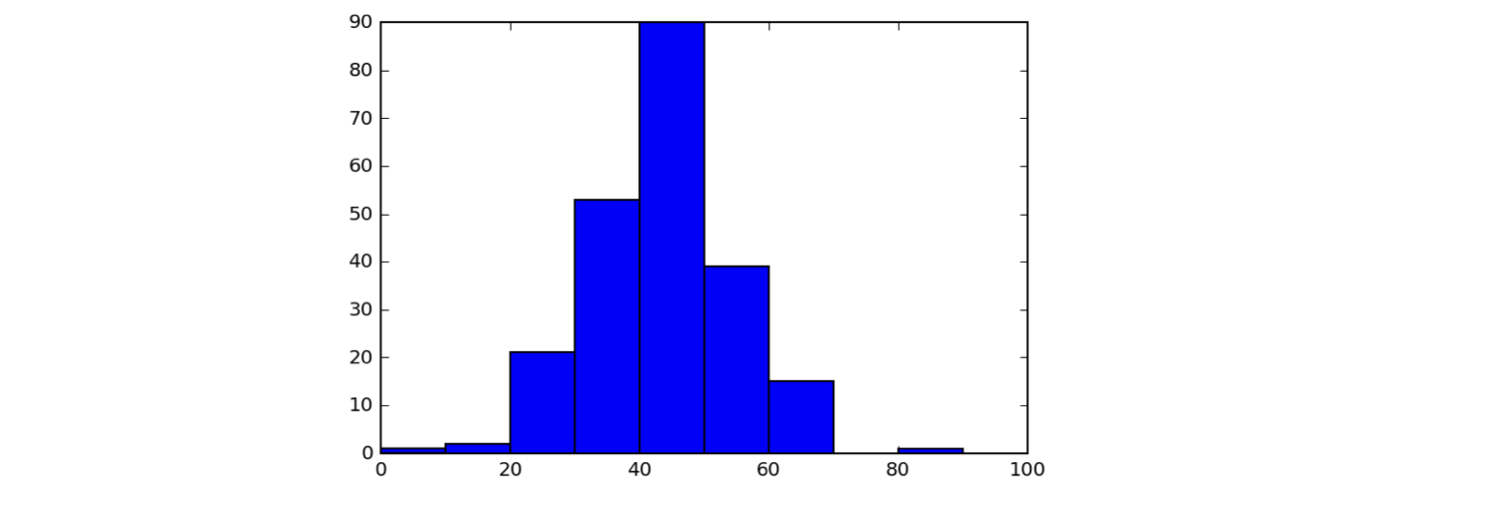
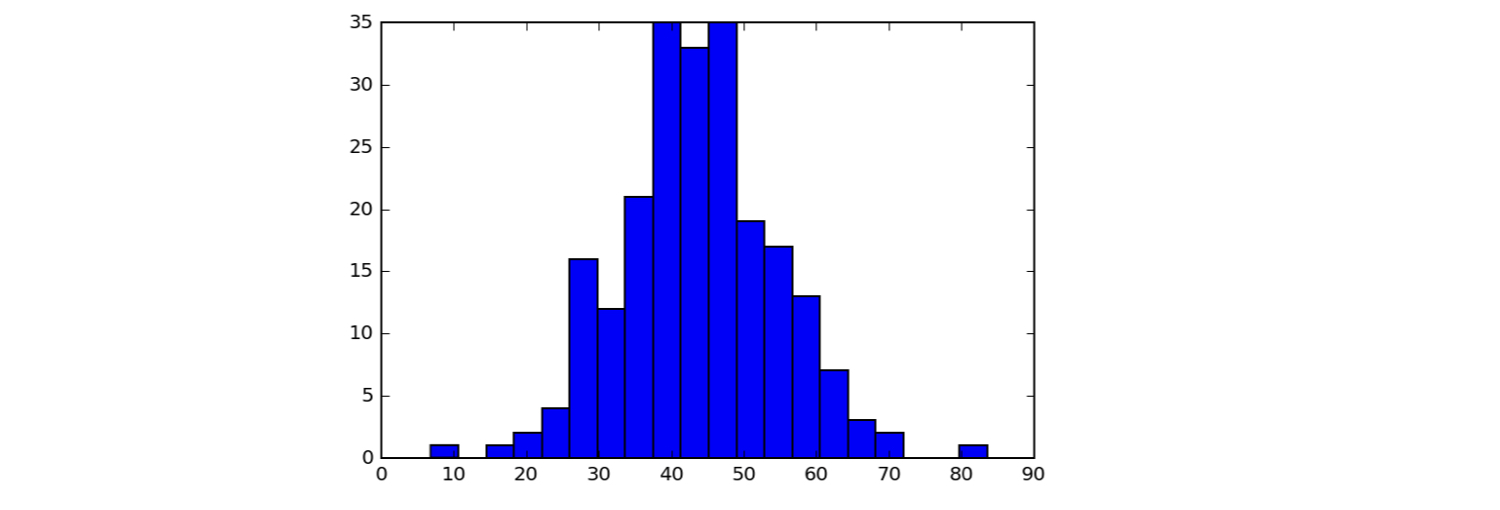
Setting the bins of a histogram
bin_edges = [0, 10, 20, 30, 40, 50,
60, 70, 80, 90, 100]
_ = plt.hist(df_swing['dem_share'], bins=bin_edges)
plt.show()
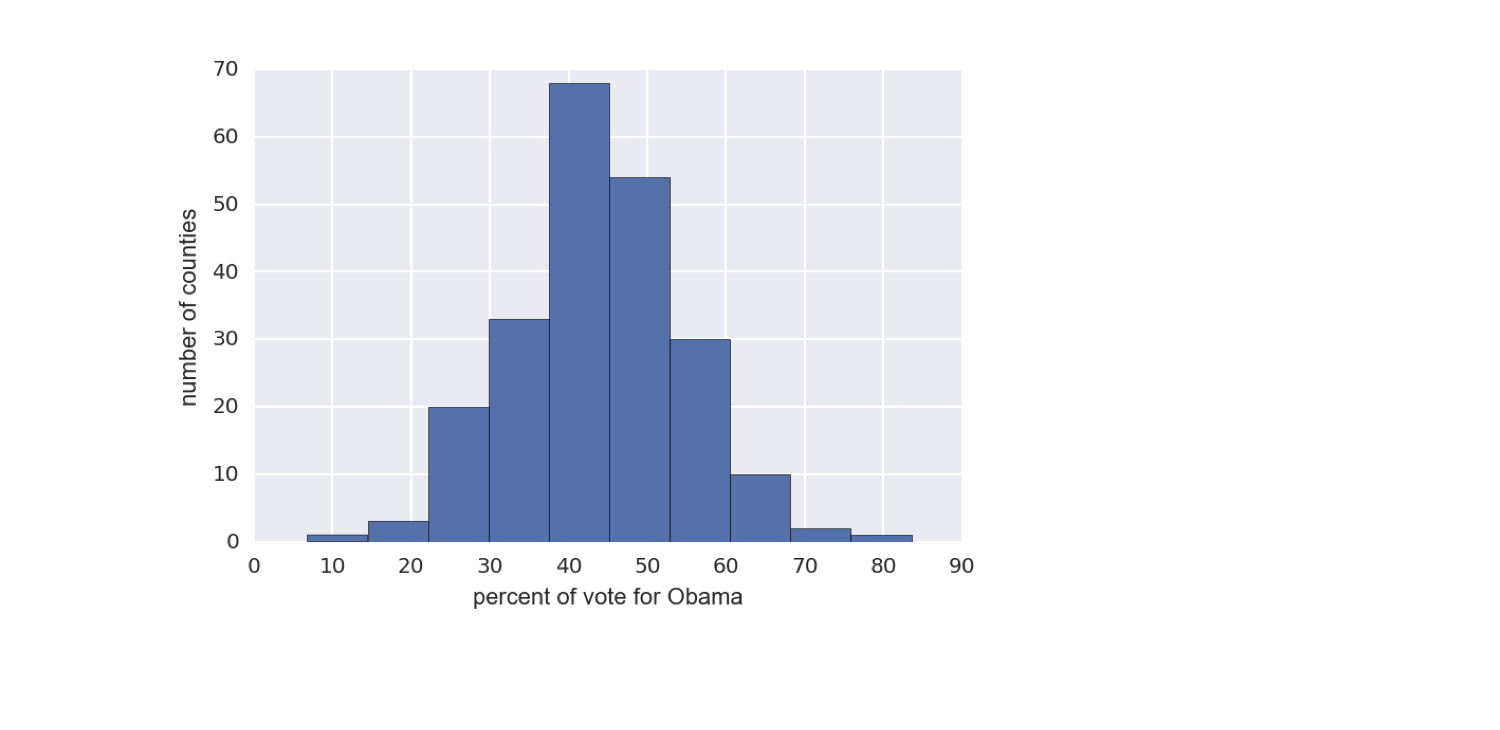
Setting the bins of a histogram
_ = plt.hist(df_swing['dem_share'], bins=20)
plt.show()
A Seaborn-styled histogram
1 Data retrieved from Data.gov (https://www.data.gov/)

