A/B testing
Statistical Thinking in Python (Part 2)

Justin Bois
Lecturer at the California Institute of Technology
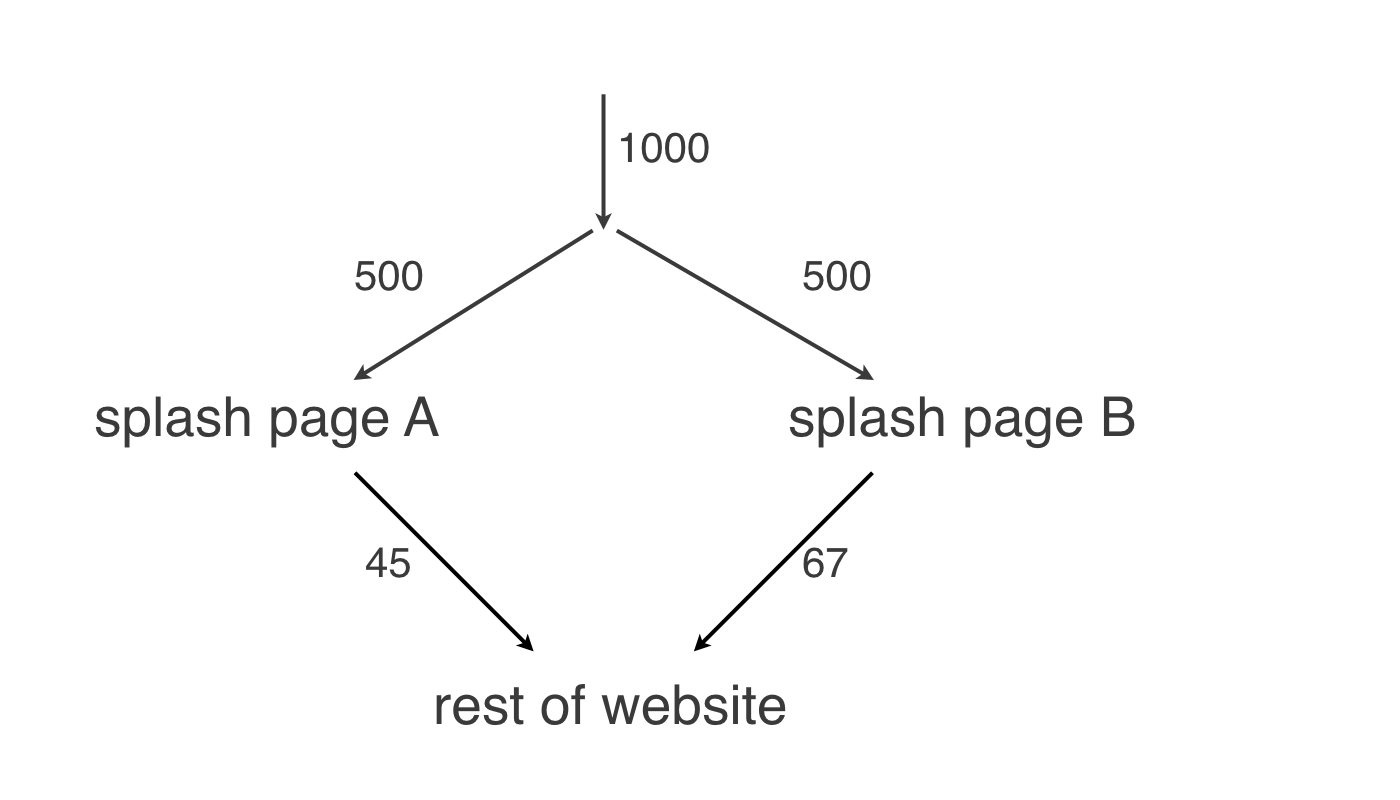
Is your redesign effective?
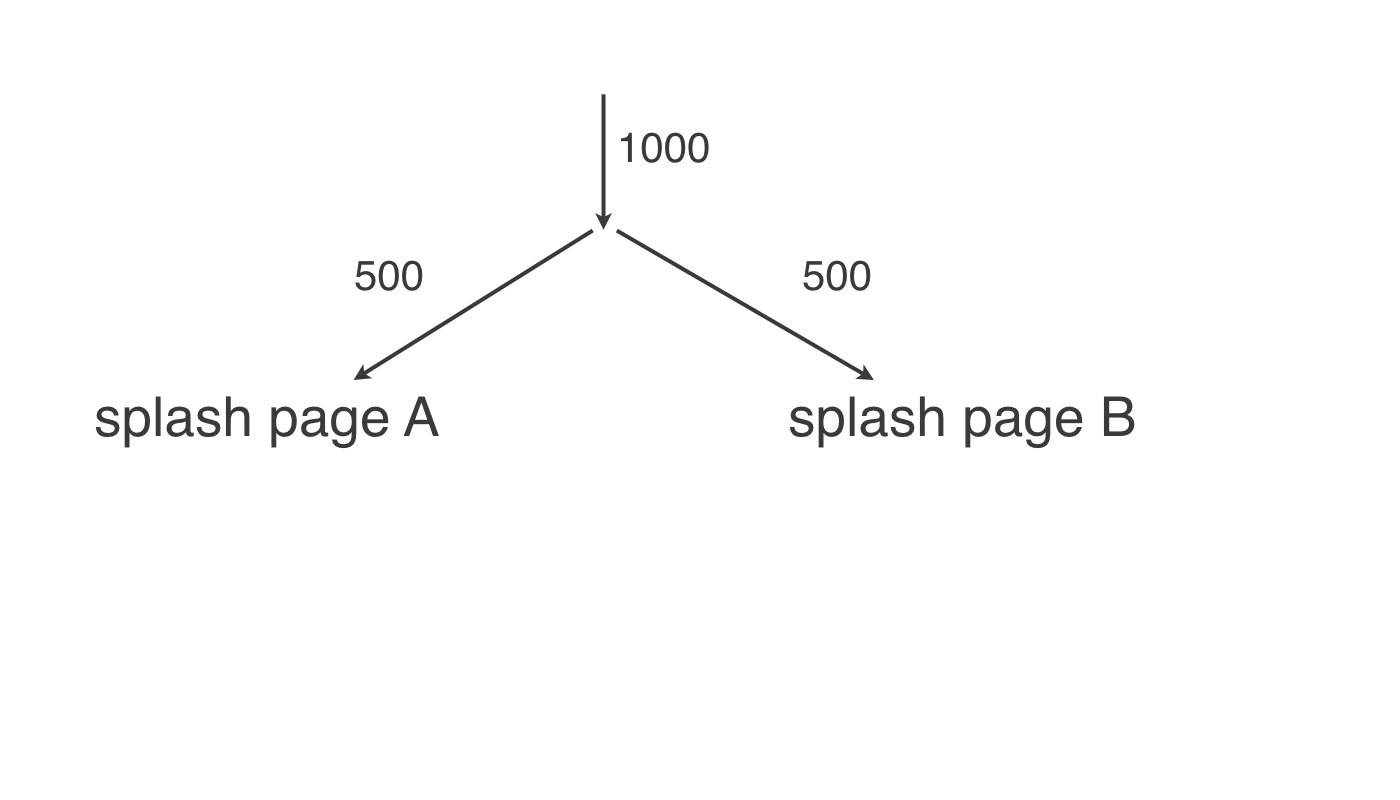
Is your redesign effective?
Statistical Thinking in Python (Part 2)
Justin Bois
Lecturer at the California Institute of Technology

