Intro to LSTMs
Introduction to Deep Learning with Keras

Miguel Esteban
Data Scientist & Founder
What are RNNs?
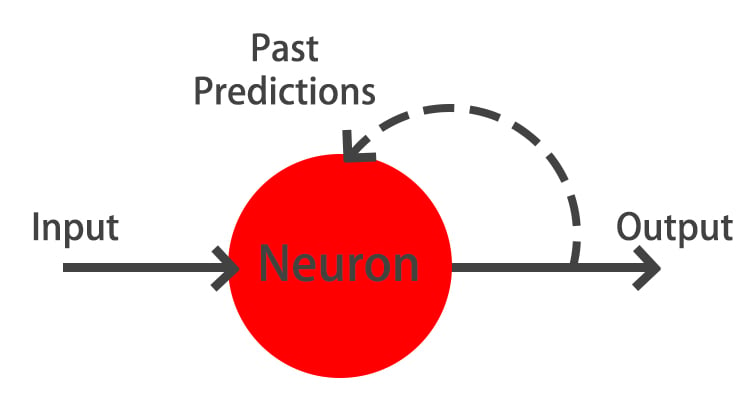
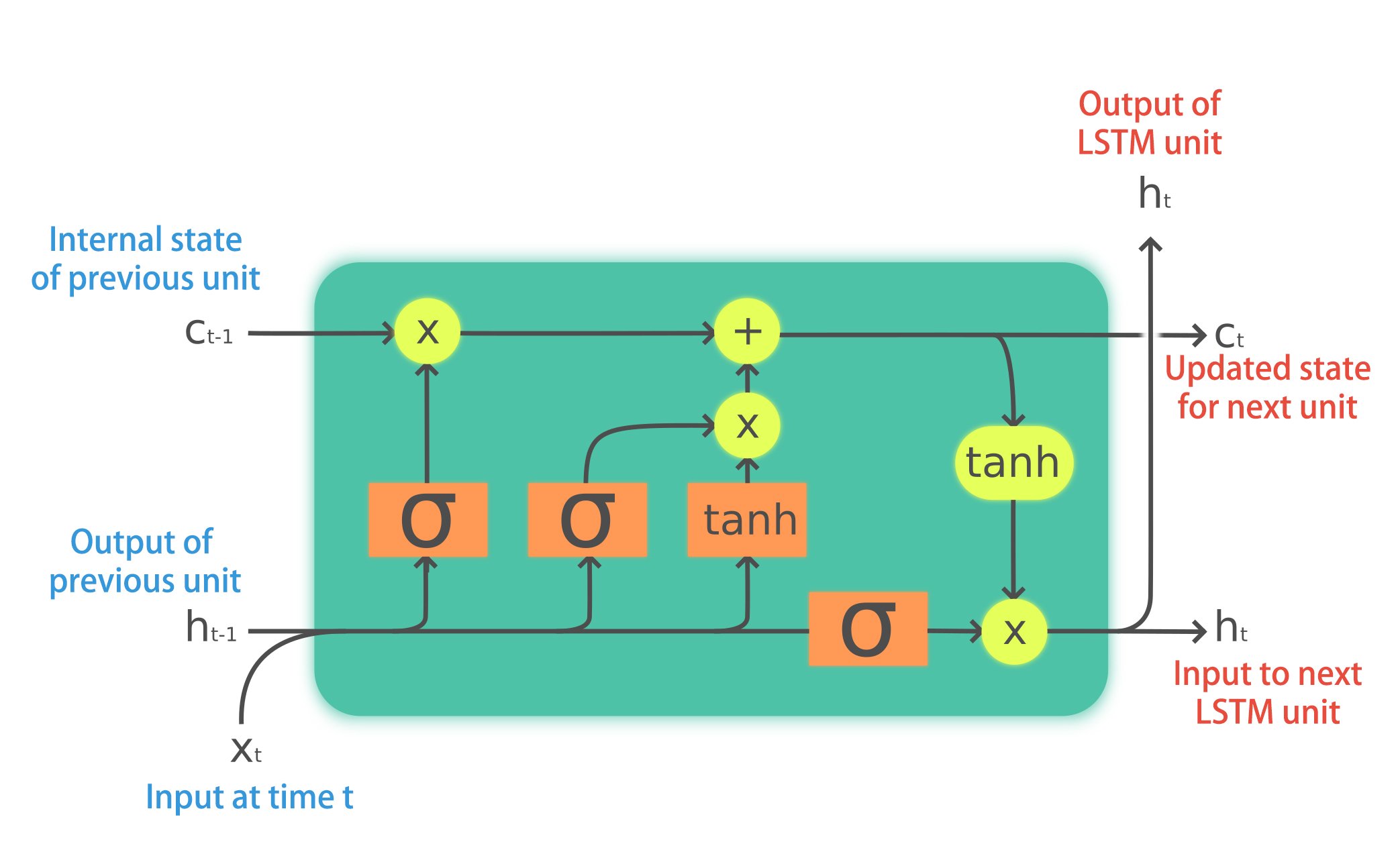
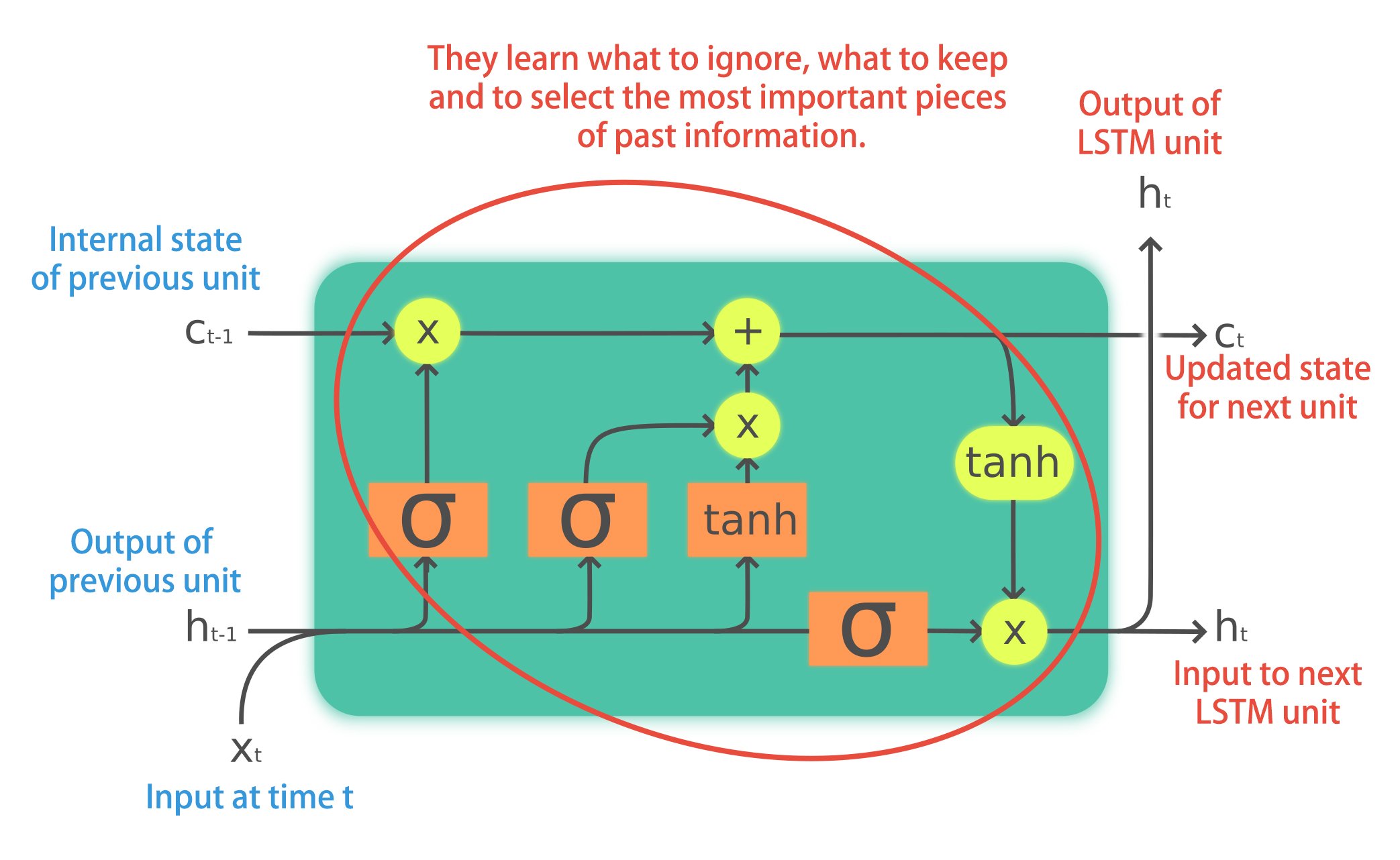
When to use LSTMs?

1 Karpathy, A., & Fei-Fei, L. (2015). Deep visual-semantic alignments for generating image descriptions.

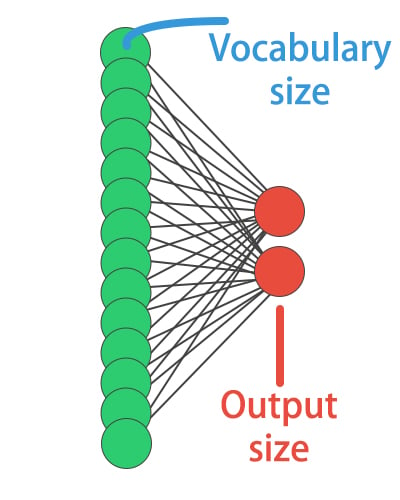
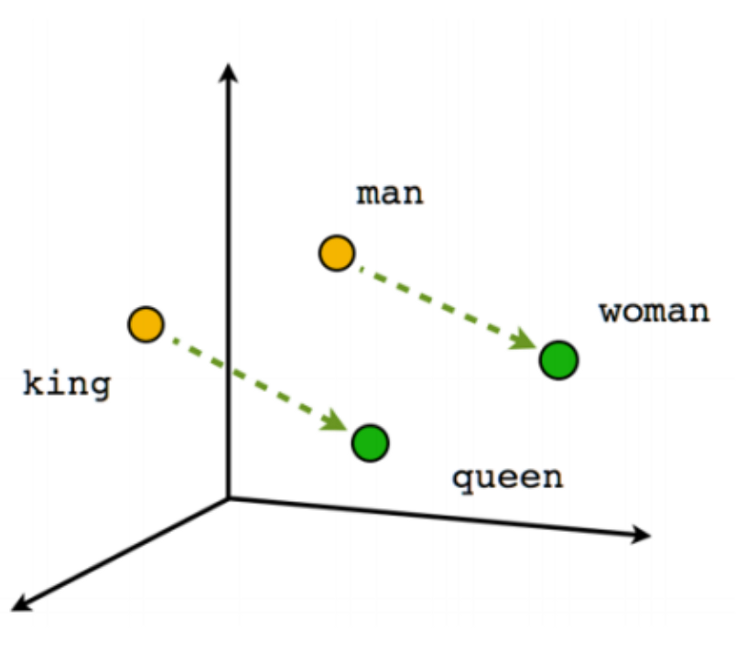
Introduction to Deep Learning with Keras
Miguel Esteban
Data Scientist & Founder

