Performing Experiments in Python
Luke Hayden
Instructor
Compare like with like
Remove sources of variation
import pandas as pd from scipy import stats seed= 1916 subset_A = df[df.Sample == "A"].sample(n= 30, random_state= seed) subset_B = df[df.Sample == "B"].sample(n= 30, random_state= seed) t_result = stats.ttest_ind(subset_A.value, subset_B.value)
Example
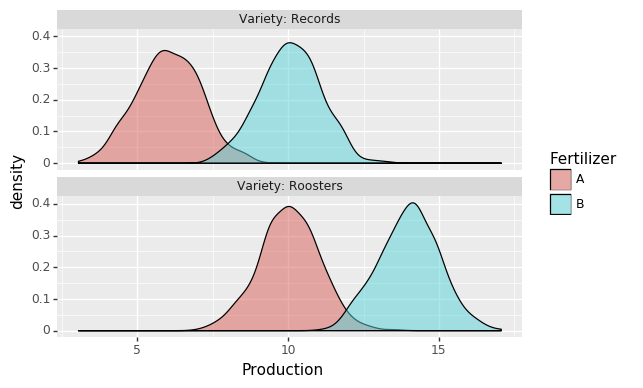
Two potato varieties: Roosters & Records
Two fertilizers: A & B
Variety could be a confounder
Design
import pandas as pd block1 = df[(df.Variety == "Roosters") ].sample(n=15, random_state= seed) block2 = df[(df.Variety == "Records") ].sample(n=15, random_state= seed) fertAtreatment = pd.concat([block1, block2])
Special case
Control for individual variation
Increase statistical power by reducing noise
from scipy import stats yields2018= [60.2, 12, 13.8, 91.8, 50] yields2019 = [63.2, 15.6, 14.8, 96.7, 53] ttest = stats.ttest_rel(yields2018,yields2019) print(ttest[1])
p-value:
0.007894143467973484