Introduction to spreadsheets
Streamlined Data Ingestion with pandas

Amany Mahfouz
Instructor
Loading Spreadsheets
- Spreadsheets have their own loading function in
pandas:read_excel()
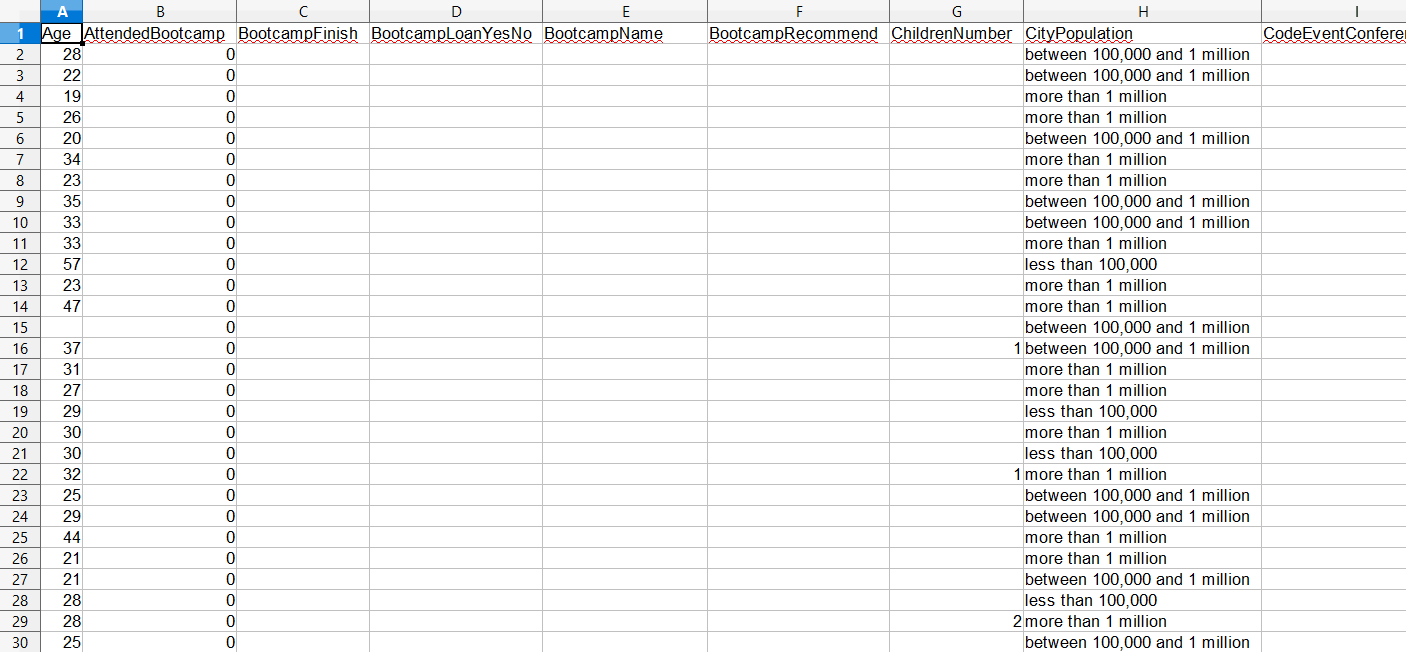
Loading Select Columns and Rows
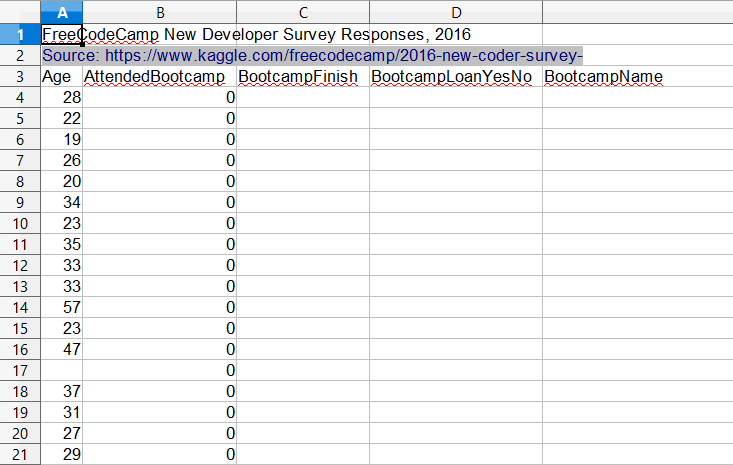
Loading Select Columns and Rows


