Leak in features – using data that will not be available in the real setting
Leak in validation strategy – validation strategy differs from the real-world situation
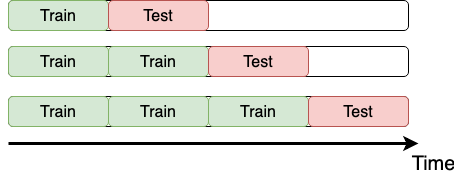
Time data
Time K-fold cross-validation
Time K-fold cross-validation
# Import TimeSeriesSplit
from sklearn.model_selection import TimeSeriesSplit
# Create a TimeSeriesSplit object
time_kfold = TimeSeriesSplit(n_splits=5)
# Sort train by date
train = train.sort_values('date')
# Loop through each cross-validation split
for train_index, test_index in time_kfold.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
Validation pipeline
# List for the results
fold_metrics = []
for train_index, test_index in CV_STRATEGY.split(train):
cv_train, cv_test = train.iloc[train_index], train.iloc[test_index]
# Train a model
model.fit(cv_train)
# Make predictions
predictions = model.predict(cv_test)
# Calculate the metric
metric = evaluate(cv_test, predictions)
fold_metrics.append(metric)
Model comparison
Fold number
Model A MSE
Model B MSE
Fold 1
2.95
2.97
Fold 2
2.84
2.45
Fold 3
2.62
2.73
Fold 4
2.79
2.83
Overall validation score
import numpy as np
# Simple mean over the folds
mean_score = np.mean(fold_metrics)