Sentiment Analysis in Python
Violeta Misheva
Data Scientist
Describes the occurrence of words within a document or a collection of documents (corpus)
Builds a vocabulary of the words and a measure of their presence
This is the best book ever. I loved the book and highly recommend it!!!
{'This': 1, 'is': 1, 'the': 2 , 'best': 1 , 'book': 2, 'ever': 1, 'I':1 , 'loved':1 , 'and': 1 , 'highly': 1, 'recommend': 1 , 'it': 1 }
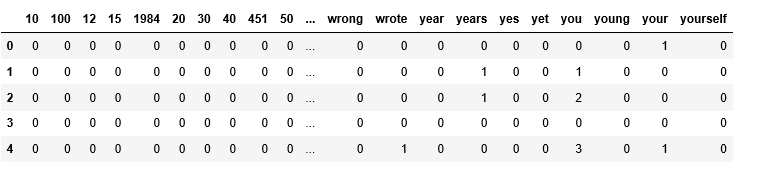
import pandas as pd from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(max_features=1000) vect.fit(data.review) X = vect.transform(data.review)
X
<10000x1000 sparse matrix of type '<class 'numpy.int64'>' with 406668 stored elements in Compressed Sparse Row format>
# Transform to an array my_array = X.toarray()
# Transform back to a DataFrame, assign column names X_df = pd.DataFrame(my_array, columns=vect.get_feature_names())