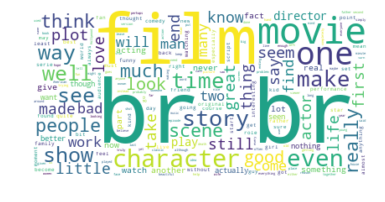
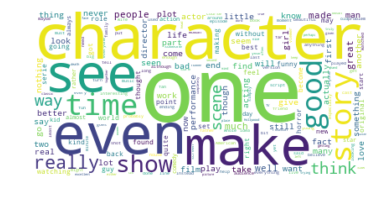
# Import libraries
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
# Define the stopwords list
my_stopwords = set(STOPWORDS)
my_stopwords.update(["movie", "movies", "film", "films", "watch", "br"])
# Generate and show the word cloud
my_cloud = WordCloud(background_color='white', stopwords=my_stopwords).generate(name_string)
plt.imshow(my_cloud, interpolation='bilinear')
Stop words with BOW
from sklearn.feature_extraction.text import CountVectorizer, ENGLISH_STOP_WORDS
# Define the set of stop words
my_stop_words = ENGLISH_STOP_WORDS.union(['film', 'movie', 'cinema', 'theatre'])
vect = CountVectorizer(stop_words=my_stop_words)
vect.fit(movies.review)
X = vect.transform(movies.review)