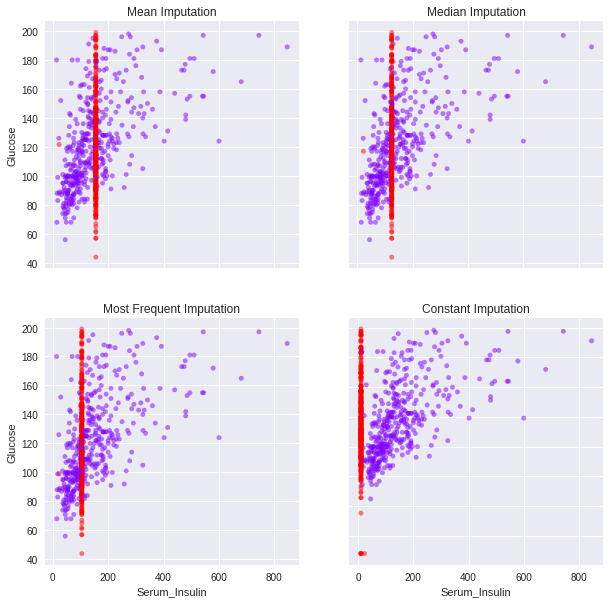
Mean, median & mode imputations
Dealing with Missing Data in Python

Suraj Donthi
Deep Learning & Computer Vision Consultant
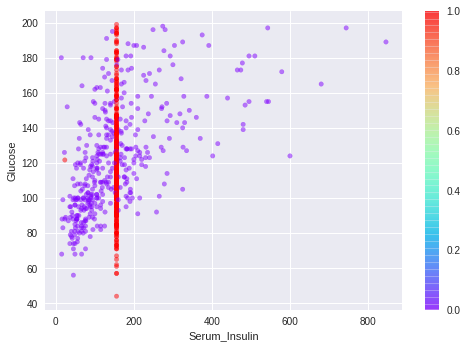
Scatterplot of imputation
nullity = diabetes['Serum_Insulin'].isnull()+diabetes['Glucose'].isnull()
diabetes_mean.plot(x='Serum_Insulin', y='Glucose', kind='scatter', alpha=0.5,c=nullity, cmap='rainbow', title='Mean Imputation')