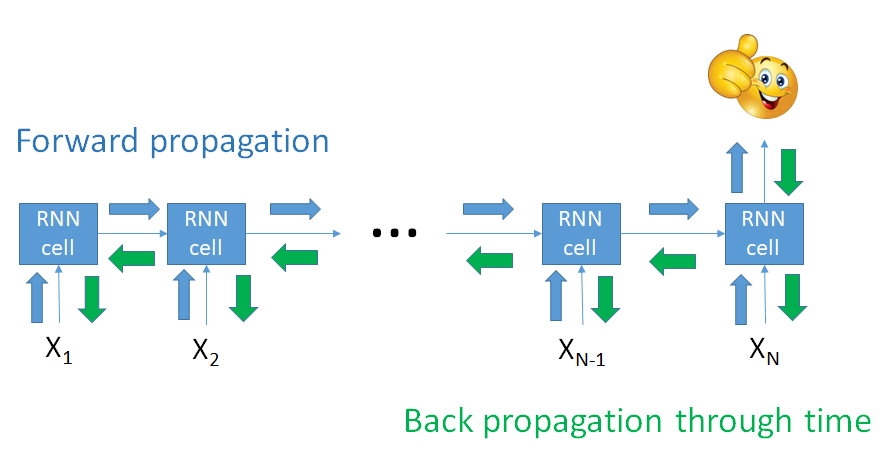
Vanishing and exploding gradients
Recurrent Neural Networks (RNNs) for Language Modeling with Keras

David Cecchini
Data Scientist
Training RNN models
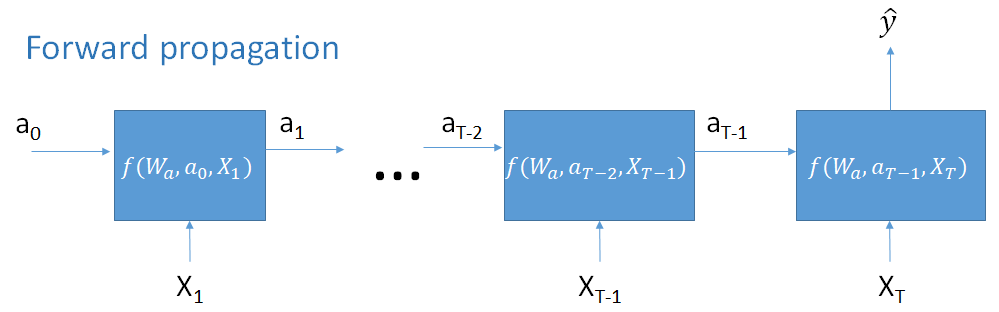
Example: $$a_2 = f(W_a, a_1, x_2)$$
$$= f(W_a, f(W_a, a_0, x_1), x_2)$$
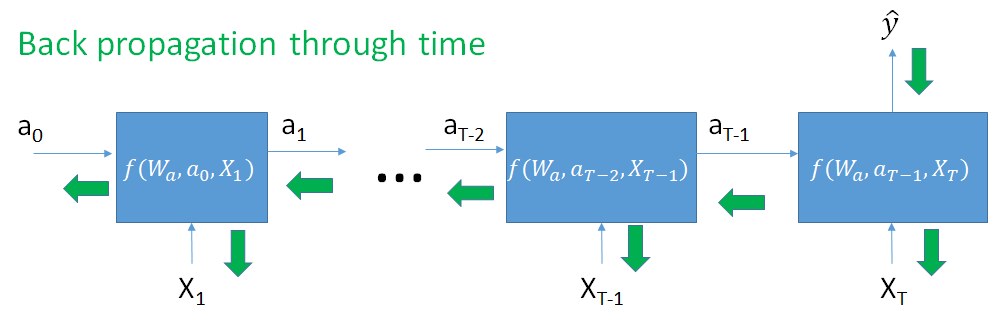
Remember that:
$$ a_T = f(W_a, a_{T-1}, x_T) $$
$a_T$ also depends on $a_{T-1}$ which depends on $a_{T-2}$ and $W_a$, and so on !

