Implementing the encoder
Machine Translation with Keras

Thushan Ganegedara
Data Scientist and Author
Understanding the data
Printing some data in the dataset
for en_sent, fr_sent in zip(en_text[:3], fr_text[:3]):
print("English: ", en_sent)
print("\tFrench: ", fr_sent)
English: new jersey is sometimes quiet during autumn , and it is snowy in april .
French: new jersey est parfois calme pendant l' automne , et il est neigeux en avril .
English: the united states is usually chilly during july , and it is usually freezing in november .
French: les états-unis est généralement froid en juillet , et il gèle habituellement en novembre .
English: california is usually quiet during march , and it is usually hot in june .
French: california est généralement calme en mars , et il est généralement chaud en juin .
Tokenizing the sentences
Tokenization
- The process of breaking a sentence/phrase to individual tokens (e.g. words)
Tokenizing words in the sentences
first_sent = en_text[0]
print("First sentence: ", first_sent)
first_words = first_sent.split(" ")
print("\tWords: ", first_words)
First sentence: new jersey is sometimes quiet during autumn , and it is snowy in april .
Words: ['new', 'jersey', 'is', 'sometimes', 'quiet', 'during', 'autumn', ',',
'and', 'it', 'is', 'snowy', 'in', 'april', '.']
Computing the length of sentences
Computing average length of a sentence and the size of the vocabulary (English)
sent_lengths = [len(en_sent.split(" ")) for en_sent in en_text]
mean_length = np.mean(sent_lengths)
print('(English) Mean sentence length: ', mean_length)
(English) Mean sentence length: 13.20662
Computing the size of the vocabulary
all_words = []
for sent in en_text:
all_words.extend(sent.split(" "))
vocab_size = len(set(all_words))
print("(English) Vocabulary size: ", vocab_size)
- A
setobject only contains unique items and no duplicates
(English) Vocabulary size: 228
The encoder
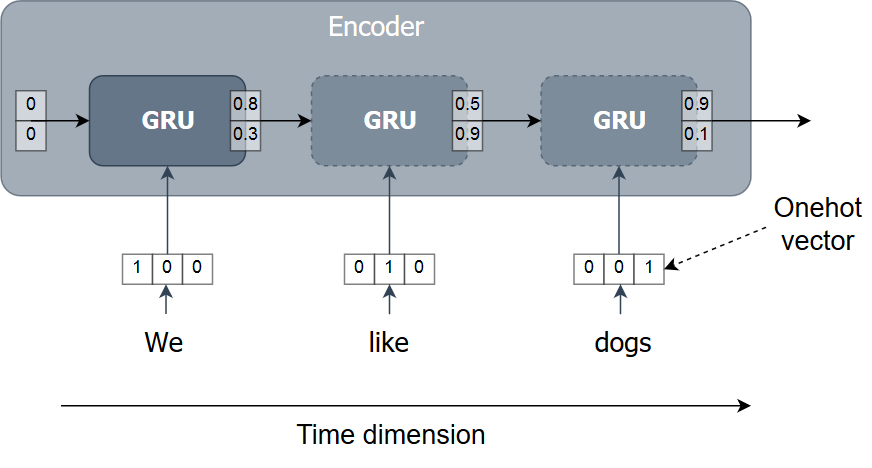
Implementing the encoder with Keras
- Input layer
en_inputs = Input(shape=(en_len, en_vocab)) - GRU layer
en_gru = GRU(hsize, return_state=True) en_out, en_state = en_gru(en_inputs) - Keras model
encoder = Model(inputs=en_inputs, outputs=en_state)
Understanding the Keras model summary
print(encoder.summary())
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 15, 150) 0
_________________________________________________________________
gru (GRU) [(None, 48), (None, 48)] 28656
=================================================================
Total params: 28,656
Trainable params: 28,656
Non-trainable params: 0
_________________________________________________________________
Let's practice!
Machine Translation with Keras

