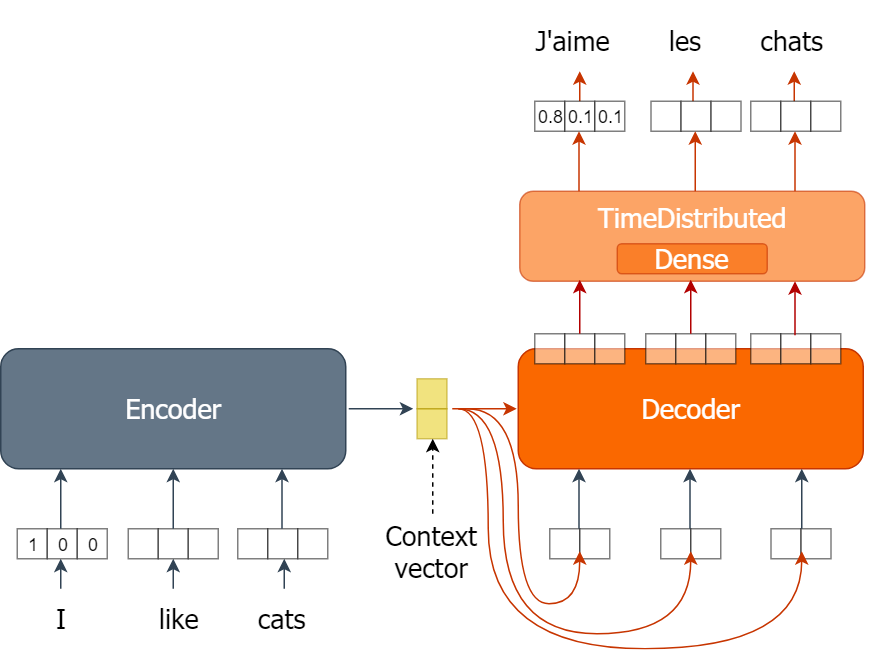
Training the NMT model
Machine Translation with Keras

Thushan Ganegedara
Data Scientist and Author
Revisiting the model
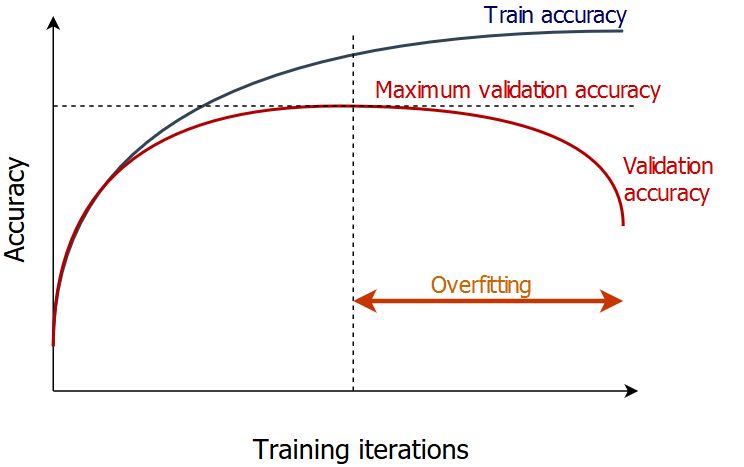
Avoiding overfitting
- Break the dataset to two parts
- Training set - The model will be trained on
- Validation set - The model's accuracy will be monitored on
- When the validation accuracy stops increasing, stop the training.