Wrap-up and the final showdown
Machine Translation with Keras
Thushan Ganegedara
Data Scientist and Author
What you've done so far
Chapter 1
Introduction to encoder-decoder architecture
Understanding GRU layer
Chapter 2
Implementing the encoder
Implementing the decoder
Implementing the decoder prediction layer
What you've done so far
Chapter 3
Preprocessing data
Training the machine translation model
Generating translations
Chapter 4
Introduction to teacher forcing
Training a model with teacher forcing
Generating translations
Using word embeddings for machine translation
Machine transation models
Model 1
The encoder consumes English words (onehot encoded) and outputs a context vector
The decoder consumes the context vector and outputs the translation
Model 2
The encoder consumes English words (onehot encoded) and outputs a context vector
The decoder consumes a given word (onehot encoded) of the translation and predicts the next word
Model 3
Instead of onehot encoding, uses word vectors
Word vectors capture the semantic relationship between words
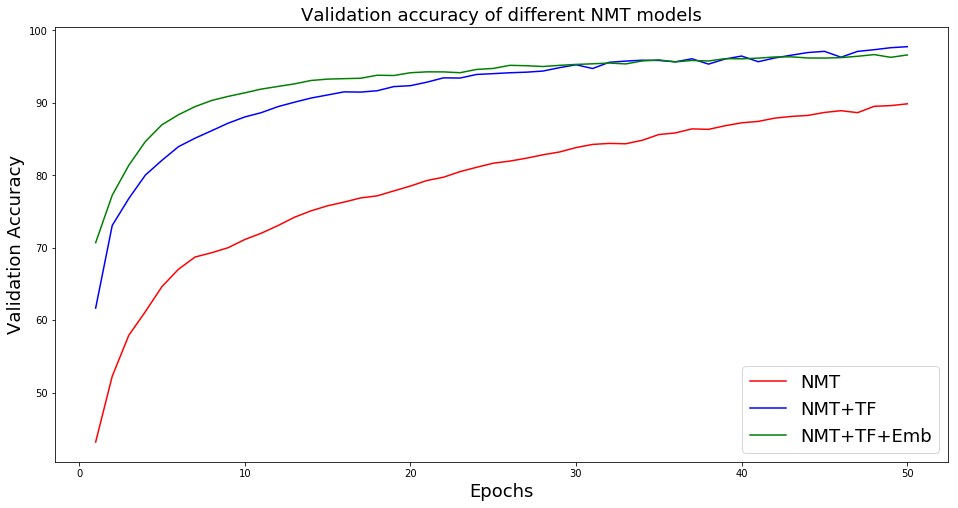
Performance of different models
Latest developments and further reading
Evaluating machine translation models
BLEU score (
Papineni et al., BLEU: a Method for Automatic Evaluation of Machine Translation.
)
Word piece models
Enables the model to avoid out of vocabulary words (
Sennrich et al., Neural Machine Translation of Rare Words with Subword Units.
)
Transformer models (
Vaswani et al., Attention Is All You Need
)
State-of-the-art performance on many NLP tasks including machine translation
Has an encoder-decoder architecture, but does not use sequential models
The latest Google machine translator is a Transformer model
All the best!
Machine Translation with Keras
Preparing Video For Download...