Part 2: Preprocessing the text
Machine Translation with Keras

Thushan Ganegedara
Data Scientist and Author
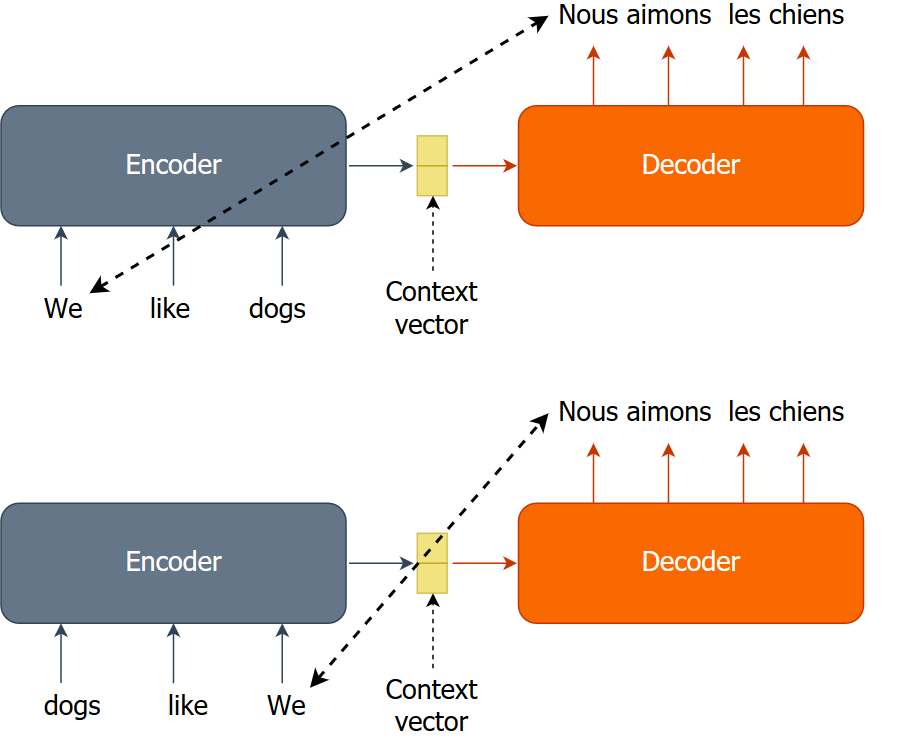
Benefit of reversing sentences
- Helps to make a stronger initial connection between the encoder and the decoder
Machine Translation with Keras
Thushan Ganegedara
Data Scientist and Author

