Credit strategy and minimum expected loss
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
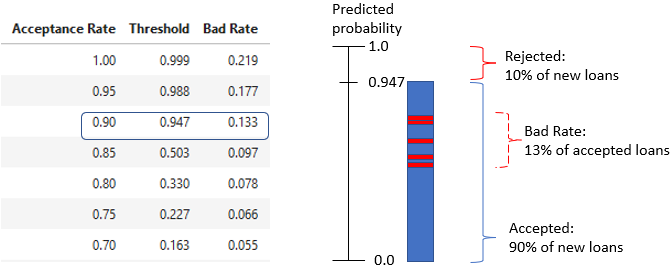
Strategy table interpretation
strat_df = pd.DataFrame(zip(accept_rates, thresholds, bad_rates),
columns = ['Acceptance Rate','Threshold','Bad Rate'])
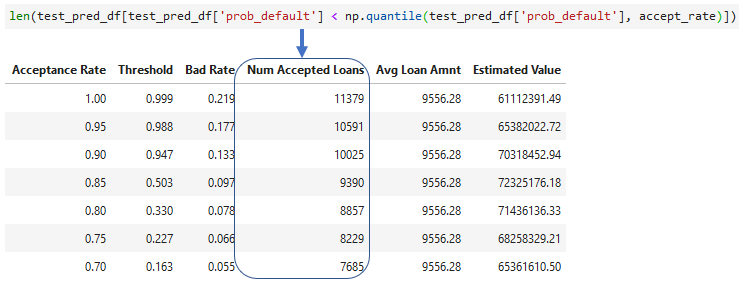
Adding accepted loans
- The number of loans accepted for each acceptance rate
- Can use
len()or.count()
- Can use
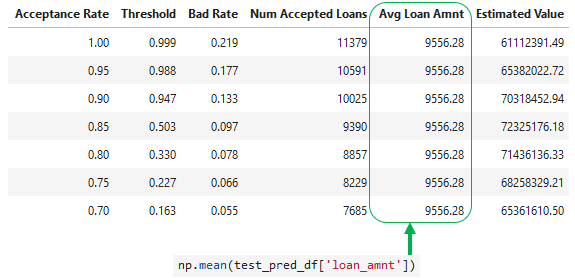
Adding average loan amount
- Average
loan_amntfrom the test set data
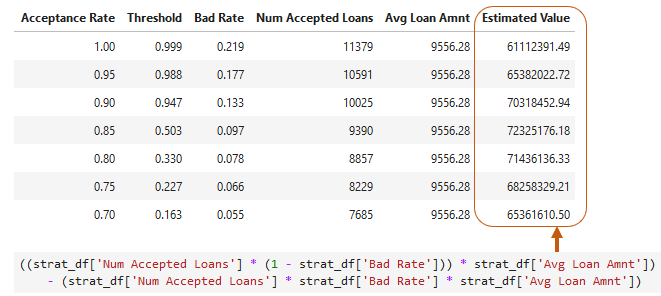
Estimating portfolio value
- Average value of accepted loan non-defaults minus average value of accepted defaults
- Assumes each default is a loss of the
loan_amnt
Total expected loss
- How much we expect to lose on the defaults in our portfolio
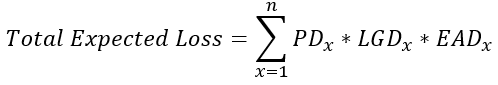
# Probability of default (PD)
test_pred_df['prob_default']
# Exposure at default = loan amount (EAD)
test_pred_df['loan_amnt']
# Loss given default = 1.0 for total loss (LGD)
test_pred_df['loss_given_default']

