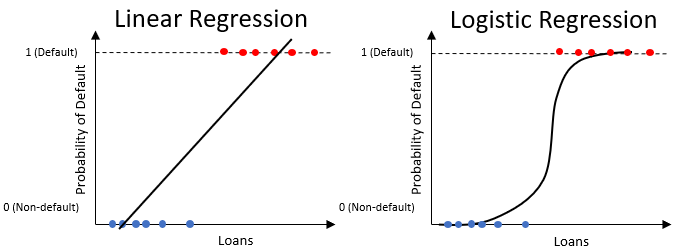
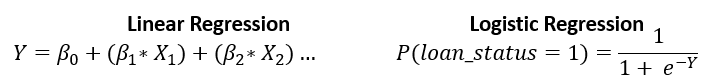Logistic regression for probability of default
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Predicting probabilities
- Probabilities of default as an outcome from machine learning
- Learn from data in columns (features)
- Classification models (default, non-default)
- Two most common models:
- Logistic regression
- Decision tree
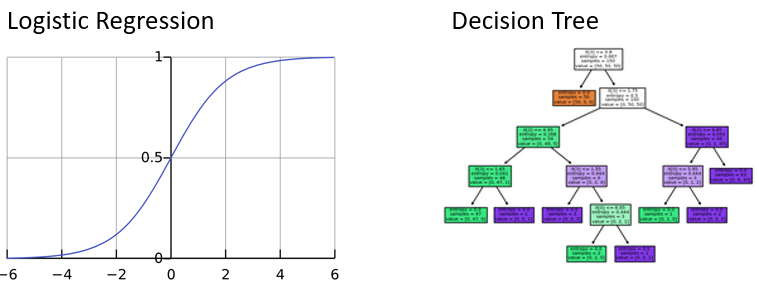
Logistic regression
- Similar to the linear regression, but only produces values between
0and1