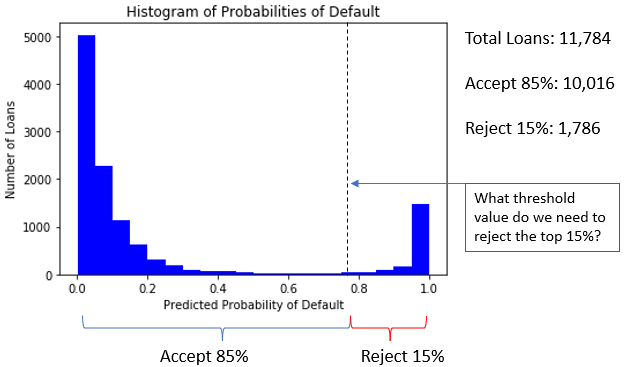
Credit acceptance rates
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Understanding acceptance rate
- Example: Accept 85% of loans with the lowest
prob_default
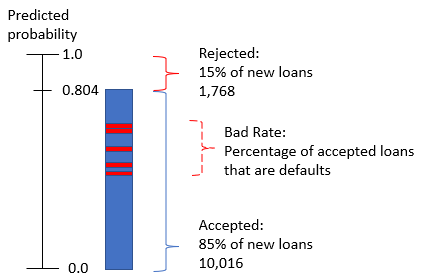
Bad Rate
- Even with a calculated threshold, some of the accepted loans will be defaults
- These are loans with
prob_defaultvalues around where our model is not well calibrated
Bad rate calculation
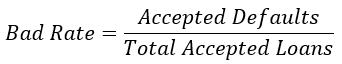
#Calculate the bad rate
np.sum(accepted_loans['true_loan_status']) / accepted_loans['true_loan_status'].count()
- If non-default is
0, and default is1then thesum()is the count of defaults - The
.count()of a single column is the same as the row count for the data frame

