Predicting the probability of default
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Logistic regression coefficients
# Model Intercept
array([-3.30582292e-10])
# Coefficients for ['loan_int_rate','person_emp_length','person_income']
array([[ 1.28517496e-09, -2.27622202e-09, -2.17211991e-05]])
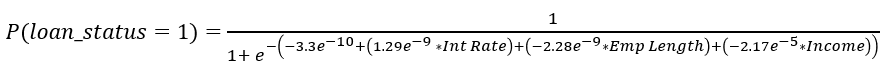
# Calculating probability of default
int_coef_sum = -3.3e-10 +
(1.29e-09 * loan_int_rate) + (-2.28e-09 * person_emp_length) + (-2.17e-05 * person_income)
prob_default = 1 / (1 + np.exp(-int_coef_sum))
prob_nondefault = 1 - (1 / (1 + np.exp(-int_coef_sum)))
One-hot encoding
- Represent a string with a number
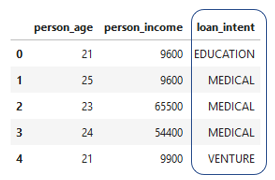
One-hot encoding
- Represent a string with a number
0or1in a new columncolumn_VALUE


