LDA in practice
Introduction to Natural Language Processing in R

Kasey Jones
Research Data Scientist
Finalizing LDA results
- select the number of topics
- perplexity/other metrics
- a solution that works for your situation
Perplexity
- measure of how well a probability model fits new data
- lower is better
- used to compare models
- In LDA parameter tuning
- Selecting number of topics
sample_size <- floor(0.90 * nrow(doc_term_matrix))
set.seed(1111)
train_ind <- sample(nrow(doc_term_matrix), size = sample_size)
train <- matrix[train_ind, ]
test <- matrix[-train_ind, ]
1 https://en.wikipedia.org/wiki/Perplexity
Perplexity in R
library(topicmodels)
values = c()
for(i in c(2:35)){
lda_model <- LDA(train, k = i, method = "Gibbs",
control = list(iter = 25, seed = 1111))
values <- c(values, perplexity(lda_model, newdata = test))
}
plot(c(2:35), values, main="Perplexity for Topics",
xlab="Number of Topics", ylab="Perplexity")
Perplexity again!
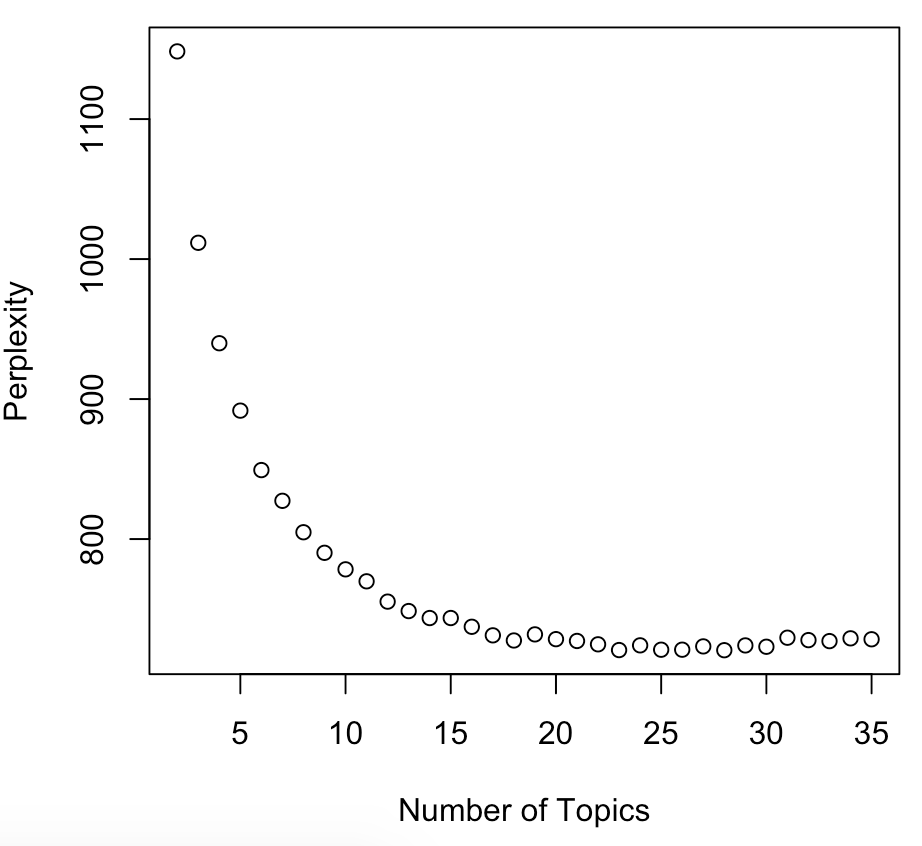
Practical selection
- How many topics can the situation handle
- 20 might be difficult to cover
- How are you displaying the results
- Graphics with 5 topics are easier than graphics with 100 topics
- Rules of thumb:
- Use a small number of topics where each topic is represented by several documents
- Large topic counts can be used only if time allows exploring and dissecting each topic
Using results
- Review or have reviewers find "themes" for each topic
- provide reviewer with a list of top words in the topic
- provide reviewer with a list of the top documents for that topic
Review output
betas <- tidy(lda_model, matrix = "beta")
betas %>%
filter(topic == 1) %>%
arrange(desc(beta)) %>%
select(term)
# A tibble: 2,000 x 1
term
<chr>
1 athletic
2 quick
3 strong
4 tough
...
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
filter(topic == 1) %>%
arrange(desc(gamma)) %>%
select(document)
# A tibble: 1,000 x 1
document
<chr>
1 232
2 292
3 921
4 643
5 468
Summarize output
gammas <- tidy(lda_model, matrix = "gamma")
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
tally(topic, sort=TRUE)
topic n
1 1 1326
2 5 1215
3 4 804
...
Summarize output again
gammas %>%
group_by(document) %>%
arrange(desc(gamma)) %>%
slice(1) %>%
group_by(topic) %>%
summarize(avg=mean(gamma)) %>%
arrange(desc(avg))
topic avg
1 1 0.696
2 5 0.530
3 4 0.482
...
LDA practice.
Introduction to Natural Language Processing in R

