Introduction to topic modeling
Introduction to Natural Language Processing in R

Kasey Jones
Research Data Scientist
Latent dirichlet allocation

1 https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
Top words continued
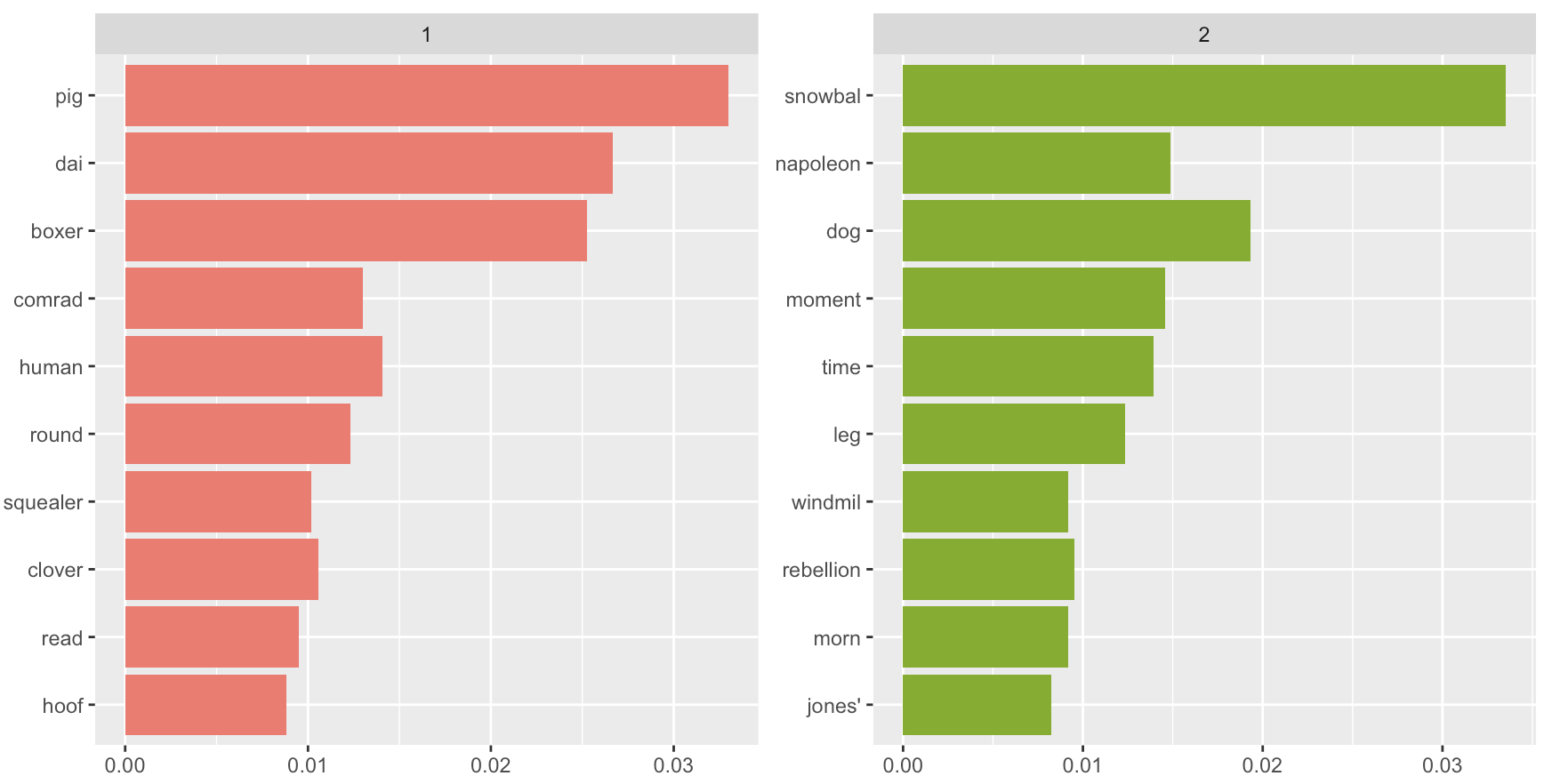
1 https://www.tidytextmining.com/topicmodeling.html

