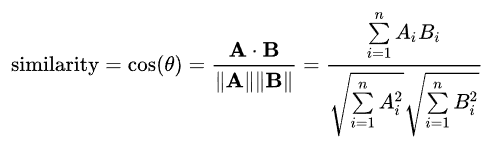Cosine Similarity
Introduction to Natural Language Processing in R

Kasey Jones
Research Data Scientist
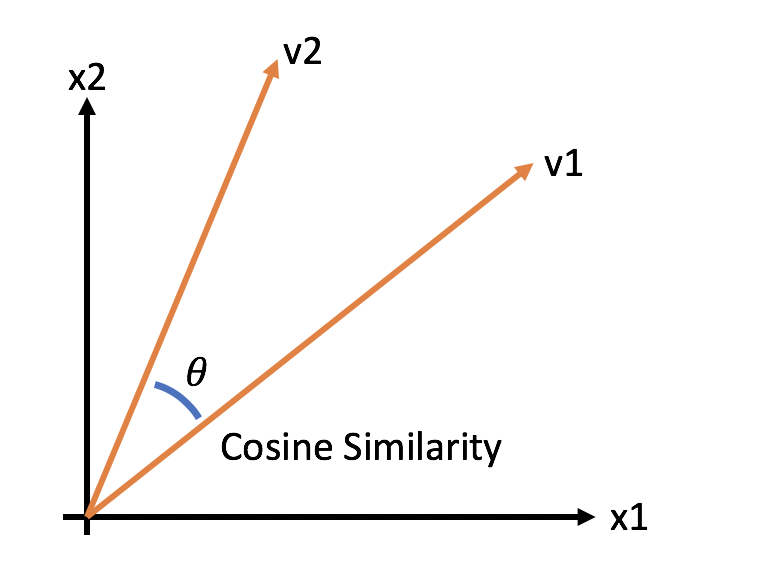
Cosine similarity
- a measure of similarity between two vectors
- measured by the angle formed by the two vectors
1 https://en.wikipedia.org/wiki/Cosine_similarity
Cosine similarity formula
- similarity is calculated as the two vectors dot product