Data preparation for purchase prediction
Machine Learning for Marketing in Python

Karolis Urbonas
Head of Analytics & Science, Amazon
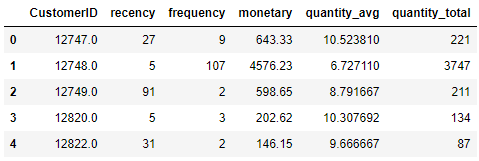
Review features
print(features.head())
Calculate target variable
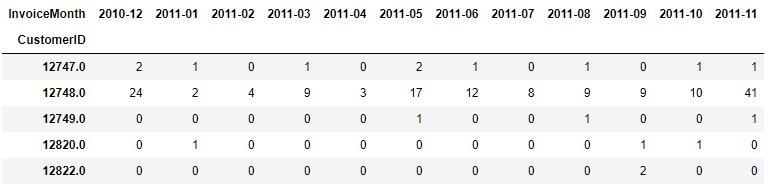
# Build pivot table with monthly transactions per customer
cust_month_tx = pd.pivot_table(data=online, index=['CustomerID'],
values='InvoiceNo',
columns=['InvoiceMonth'],
aggfunc=pd.Series.nunique, fill_value=0)
print(cust_month_tx.head())